LLM強化学習(RL)とは?LLMの精度を上げるための手法について網羅的に解説!


ここ最近では、人工知能の発展が目覚ましく、人間のように様々なタスクに対応できるAGI(汎用人工知能:Artificial general intelligence)や、人間の知能をはるかに超えたASI(人工超知能:Artificial Superintelligence)というAIの議論をさらに一歩前に進めるような言葉を聞くようになりました。
AIの進化に関しては、LLMの進化がそれを下支えしていることは言うまでもなく、より人間にとって使いやすいように学習が繰り返され精度がどんどん向上しています。
LLMの学習については、従来の「教師あり学習」から「強化学習」によってなされるようになり、それにより大きく進化、LLM学習におけるパラダイムシフトが起こっています。
今回は、LLMの精度を上げるための強化学習について解説いたします。
目次
LLM強化学習とは?

LLM強化学習とは、LLMが最適な結果を達成するためにソフトウェアが意思決定を行うよう訓練する機械学習技術のことです。最適な結果とは、つまり、人間にとって望ましい応答をLLMが出力することです。人間の手によるフィードバックや報酬に基づいて、回答を改善する方法として強化学習が注目されています。また、人間さながらの感覚を持つLLMによって改善される方法なども最近は登場しています。
強化学習はRLと略されることも多く、英語ではReinforcement Learningといいます。
学習においては、LLMが「エージェント」という役割を担い、ある環境の中で最良の結果を得られるように学んでいきます。そして、エージェントはポリシー(方策)を定め、それをもとに行動していきます。
LLM強化学習を理解するために重要なのは、『意思決定を行う「エージェント」が、ある環境の中で「行動」をとると、環境の中の「状態」が変化し、その結果得られるものが「報酬」である』という概念です。
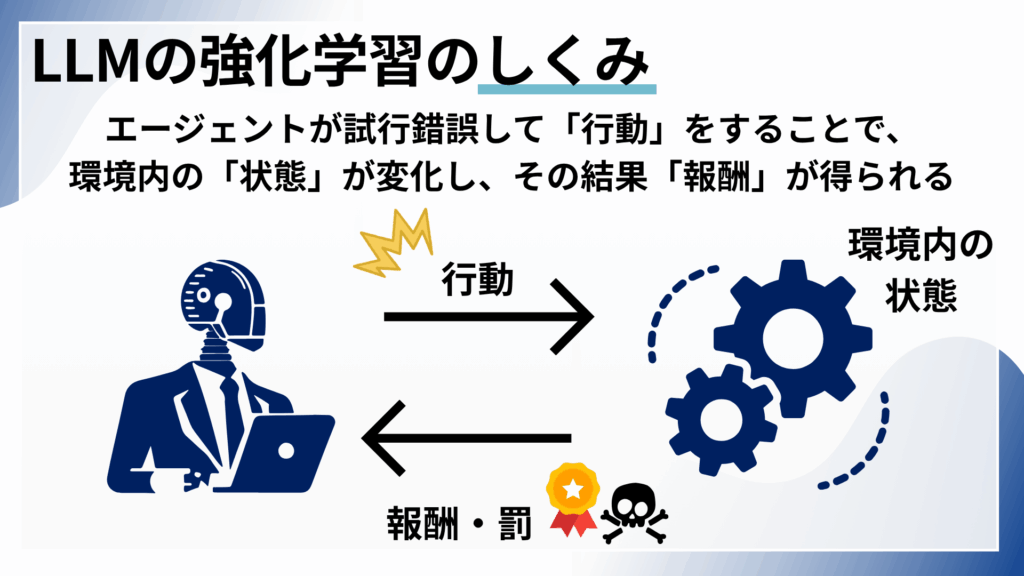
LLM強化学習の方法
強化学習は、人間や動物が目標を達成するために用いる試行錯誤の学習プロセスを模倣しています。目標を達成するためには、必要なソフトウエアアクションとそうでないものを判断し、最終的に最適な結果を導くようにします。これまでの結果の全ての合計である「累積報酬(Cumulative Reward)」を最大化するのが、強化学習の目指すところです。
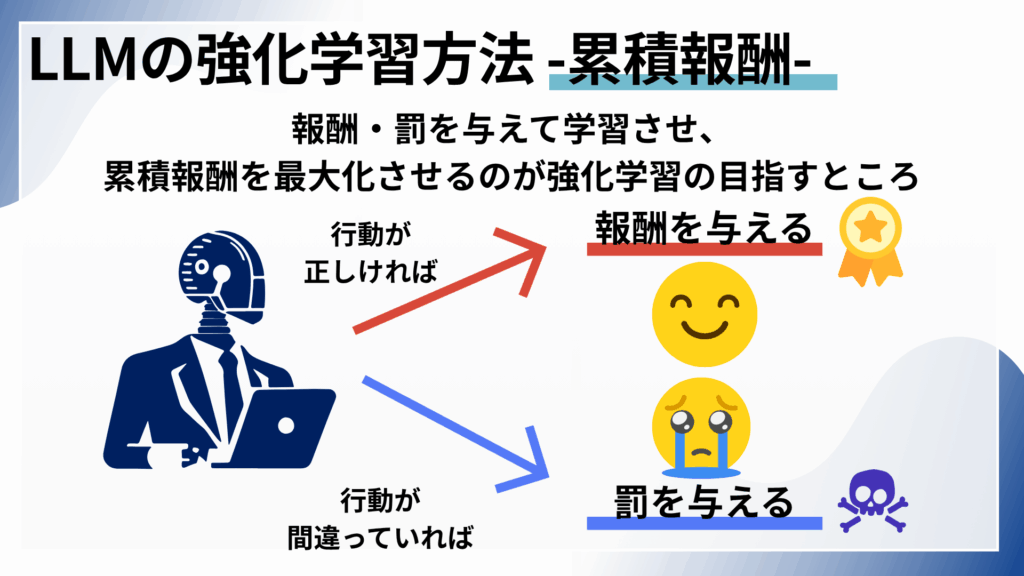
強化学習のアルゴリズムは、データ処理において「報酬」(有用性、無害性、真実性、人間の好みへの合致度を数値化したフィードバック)と「罰」のパラダイムを使用し、各行動のフィードバックから学習することで、最終結果を達成するための最適な処理経路を自ら発見します。
さらに、強化学習の特筆すべき点は、「遅延報酬(Delayed Gratification)」、つまり、回答を先延ばしにすることで得られるメリットが高いと判断した場合に目の前の利益を「犠牲」したり、「罰」を受けたり後戻り対応ができる能力も持ち合わせているということです。
どの情報を出すべきか、または出さないべきなのかを判断しているのが、まさに人間のように感じられます。
このように、LLMの強化学習は、LLMが目に見えない環境で最適な結果を達成できるようにする手法といえます。
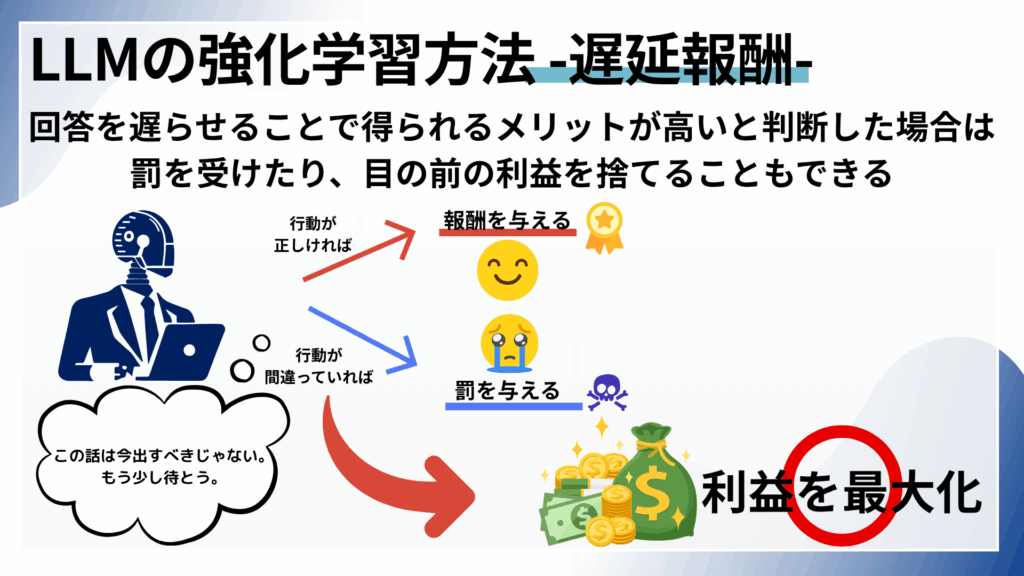
こちらの記事では深く言及はしませんが、「報酬」「罰」を得て学習していく方法は、マルコフ決定過程モデル(Markov Decision Process:MDP)と呼ばれます。
LLMの強化学習において、結果が不確実な状況で、最善の行動を連続して選択していくためのモデルであるMDPが強化学習の基礎となっています。この方法の基礎になっているのは、「未来の状態は、過去の履歴には関係なく、現在の状態と行動によってのみ決まる」とマルコフ性という考え方です。
LLM強化学習と教師あり学習の違い
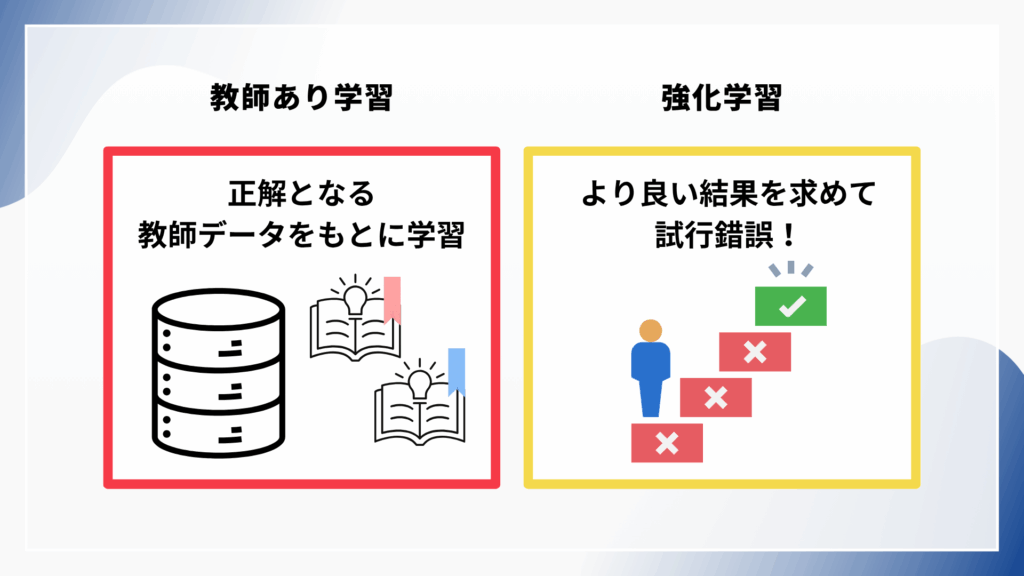
LLM強化学習と教師あり学習の違いを理解しておくことで、これから解説するLLM強化学習の重要性を理解することができます。
教師あり学習
まず、教師あり学習とは、教師データ(Teaching Data)を用いてAIを学習するものです。入力と期待される関連出力の両方を定義し、ラベル付けされた(アノテーションされた)正解となる教師データを学習することでAかBかを判定できるようになります。
教師あり学習のアルゴリズムは、入力・出力のペアデータの関係性を学習することで、新しい入力データの結果を予測して学習します。一方で、教師なし学習は正解となるデータは与えられずに、与えられたデータをそのまま学習する方法を指します。
つまり、教師あり学習は、テストのために決まったテキストや教科書を使って学習していくような方法といえるでしょう。
強化学習
強化学習は、教師あり学習とは異なり、正解データがなく、目的として設定された望ましい結果、つまり「報酬(スコア)」を最大化するための行動を学習する手法です。このため、アノテーション(ラベル付)をする必要はなく、AIが自分で試行錯誤しながら最適なシステム制御を学んでいくような学習手法です。
入力を既知の出力に位置付ける代わりに、入力を潜在的な結果に位置付けることで学習を深めます。例えば、囲碁や卓球をするAIロボットでは、行動パターンを実際のプレイを通じて学び、その動きを学習・予測して実行し、その動きがどうであったかを振り返ることで学習を深めていきます。
つまり、強化学習は、ある成し遂げたい研究テーマがあって、そのために自ら情報を探し求めてリサーチをするような方法と言えます。
LLMにおける強化学習の重要性:アライメント問題とHHH原則
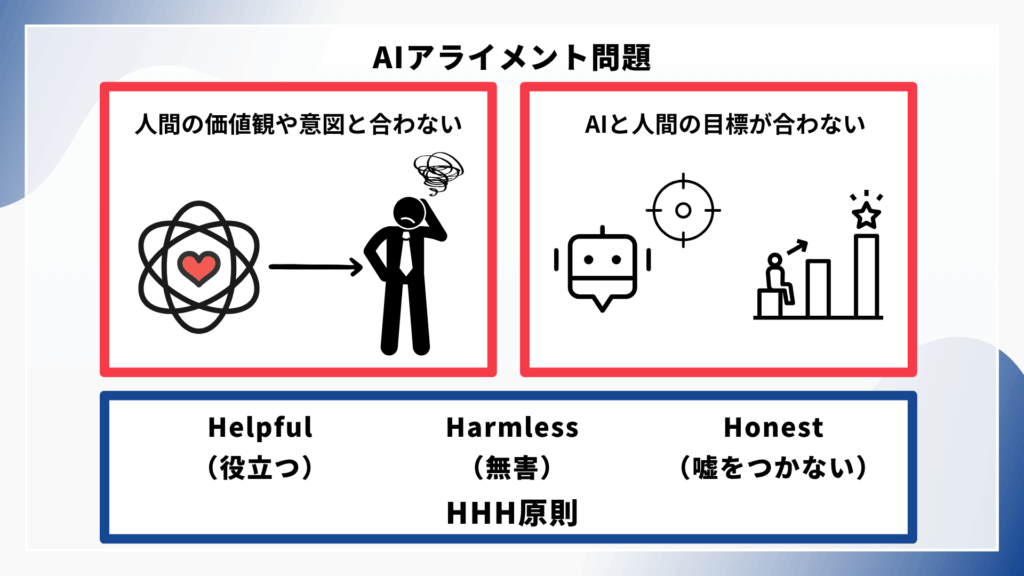
アライメント問題とは?
LLMの開発において最も重要な課題の一つといえるのが、アライメント問題(Alignment problem)です。
例えば、LLMに細かく条件設定をして投げかけても思った通りの考え方をしてくれない、動いてくれないということはありませんか?このように、LLM利用者や作成者の意図やシステム本来の意図とは一致しない偏った有害で不正確な出力を行うことがあります。
アライメント問題とは、LLMの行動が人間の意図や目的、価値観、嗜好と整合しない問題を指します。
HHH原則(Helpful/Harmless/Honest)
そのアライメント問題については、HHH原則がLLMの開発を下支えする考え方となります。
HHHとは英単語3つの頭文字をとったもので、
「Helpful(役立つ):ユーザーの意図を正確に理解し、有用な情報や支援を提供すること」
「Harmless(無害):差別的、攻撃的、違法なコンテンツを生成しないこと」
「Honest(正直):事実に基づく情報を提供し、不確実性を適切に表現すること」
のことを指します。
この原則を踏まえてアライメント問題を捉えることがLLM強化学習にとって、とても重要です。
これまでのLLM学習
なぜLLM強化学習が有効であるのか、という話の前にまずは従来のLLM学習の方法について紹介します。
LLMの学習は基本的に事前学習(Pre-Training)とファインチューニング(Fine tuning)の2段階で学習されています。
事前学習(Pre-Training)はLLMの初期段階として、インターネットなどから膨大な量のテキストデータを学習して、言語の一般的な構造やパターンと汎用的な知識を学習するプロセスです。
事前学習の後、ベースモデルがさまざまなタスクや応答に応えられるようにファインチューニング(Fine tuning)を行います。特定のデータセットを学習させることで、その分野のタスクに対応できるようになります。この段階では、人間が作成した高品質な質問―回答データのペアを用いてLLMを指示や特定のタスクに従わせるようにします。似たような質問をされた際に推論を行ってそれを繰り返すことでモデルの訓練をしていきます。
LLMが抱える露出バイアスという課題
従来のLLMの学習では、露出バイアス(Exposure Bias)が根本的な問題がありました。つまり、誤ったものに遭遇したときに対処する能力がないということです。
例えると、何度も解いた英語の問題集の問題は解けるけれども、違う形式の問題に出会うと途端に解けなくなってしまう(ミスを犯してしまう)というもの。
普段は正しいものとされている言葉を学習していても、途端に普段は使われない言葉の並びやスラングに出会うと訳がわからなくなってしまう、ということがあります。
AIにおいても同様で、それがLLMの抱える露出バイアスという問題です。訓練時と推論時でモデルの露出が異なることで「わからない!」となってしまうのです。
統計的に言語を生成するLLMの限界
さらにLLMには構造的な限界があります。LLMが大規模なデータから統計的学習と確率的言語生成というアプローチを採っているがゆえに、様々な問題が発生してしまうのです。
LLMは基本的に最大尤度推定のもと動きます。つまり、「一番もっともらしい」という結果を出すために動くのですが、統計的に正しいとされているものが、人間界では望ましくない結果となることもあるからです。誤情報、偏見、有害な情報がたくさんインターネット上にはあり、それをLLMは学習してしまっていることもあります。データ数が多いとはいえ、人間の価値観として正しい、または、好みを必ずしも直接的に反映していない出力がされることもあります。
また、LLMは複雑な推論タスクの場合は長期的に論理的一貫性を保てないという弱点もあります。ChatGPTと長い会話を続けていると、「さっき伝えたことを忘れてしまっている」ということがありますよね。
これは、LLMは局所的に最適化され、記憶しておくためのスペースが限られているからで、その結果、全体的な論理の整合性を保証できないという問題があります。
なぜLLM強化学習が必要なのか?

上記で述べたように、これまでの学習では様々な課題や限界がありました。
LLMにとっての強化学習は、多くの人が生成AIを利用していて感じているような「思ったのと違う」というようなLLMの言動を改善するためにあります。
自然言語でチャットができる現在のLLMは、話す相手は人間です。たとえ言葉で書かれたものが同じであっても、その言葉の背景は人によって、そして環境や文化によって大きく異なる場合もあるでしょう。また、言葉は文脈にかなり依存しているため前後の内容によってその言葉が示していることは違うこともあります。
強化学習は、事前学習・ファインチューニングが終わったモデルが、人間にとって望ましい回答をするように学習させるフェーズといえます。
人間の言葉を理解するためには、人間によるフィードバックを直接的に学習プロセスに組み込むことで、この複雑な価値観の学習を可能にします。後述しますが、最近では人間同様の判断ができるAIによるフィードバックができる手法も開発されています。
このように、強化学習では、人間やAIがモデル出力を評価し、その評価を報酬信号として用いることで、文章には現れてこない言葉の裏にある価値観や背景情報の判断基準を学習できるのです。
LLMにおける主要な強化学習法
ここからは、LLMの主要な強化学習方法について紹介します。

人間のフィードバックによる強化学習 (RLHF)
RLHF(Reinforcement Learning from Human Feedback:人間によるフィードバックからの強化学習)は、人間のフィードバックを活用して機械学習モデルを最適化し、より効率的な自己学習を可能にする強化学習の手法です。この手法では、強化学習の報酬関数に人間の入力が組み込まれます。
AIは「人間を模倣し、人間のようになること」が最終目標であるといえるでしょう。
RLHFでは、モデルの応答と人間の応答を比較し、その後、出力される応答に対して人間がその品質を評価します。
たとえば、統計上で「面白い」という結果は導き出すことが難しいですが、人間による評価を使うことで、LLMのジョークの面白さを向上させることができます。
図9-1024x576.png)
LHFにおいては、人間の好みを数値的な報酬記号に変換する報酬モデルを作成する必要があります。
当たり前のことではあるのですが、人間の主観的な価値観を適切に定義するための数学的・論理的な公式は存在しません。
だからこそ、効果的な報酬モデルを設計できるかどうかというのが、RLHFにおいて重要なステップといえます。
LLMを評価するための単純なシステムでは、ユーザーが各出力を「高評価」または「低評価」判断をし、相対的な好感度によって出力が格付けされる場合があります。
複雑なシステムでは、評価ラベル作成者に具体的かつ全体的な評価、各回答の欠陥に関するカテゴリ別の質問に回答するよう依頼したのち、このフィードバックをアルゴリズム的に集計して品質スコアを作成する場合があります。
近接方策最適化 (PPO)
RLHFについて理解を深めるために、PPOについて紹介します。
PPO(Proximal Policy Optimization:近接方策最適化)は、RLHFでの強化学習のプロセスの中で使われるアルゴリズムです。
PPOは、「クリッピング」という手法を使うことで、新しい方策が古い方策から逸脱しないように方策の改善率を一定の範囲内に制限する(損失関数を最小化する)ポリシーベースの強化学習アルゴリズムとなっています。
RLHFでは、LLMがまず人間のフィードバックを基に報酬モデルを学習します。その報酬モデルをPPOなどの強化学習アルゴリズムを使用して、報酬信号が最大化するように出力を学習します。
学習の過程において、LLMが自身の出力に対して「報酬」または「罰」を受けとり、それを繰り返していくことによって、将来的に得られる報酬の合計が最大化できるようポリシー(行動方策)を最適化していきます。その方法がPPO(近接方策最適化)です。
AIフィードバックによる強化学習 (RLAIF)
図10-1024x576.png)
先述したように、人間によるフィードバックは最近ではAIに置き換えて行うことができるようになりました。AIフィードバックによる強化学習(Reinforcement Learning from AI Feedback, RLAIF)は、強化学習のプロセスにおいて、LLMが他のLLMにフィードバックを提供する機械学習技術であり、人間によるフィードバックに置き換わる強化学習の手法です。
LLMが近年より高性能になり、人間によるフィードバックの不完全さがボトルネックとなるにつれて、フィードバックループを自動化することで訓練を効率化・コストを削減し、性能を向上させることができるという考え方のもとRLAIFが注目を浴び始めています。
直接選好最適化 (DPO)
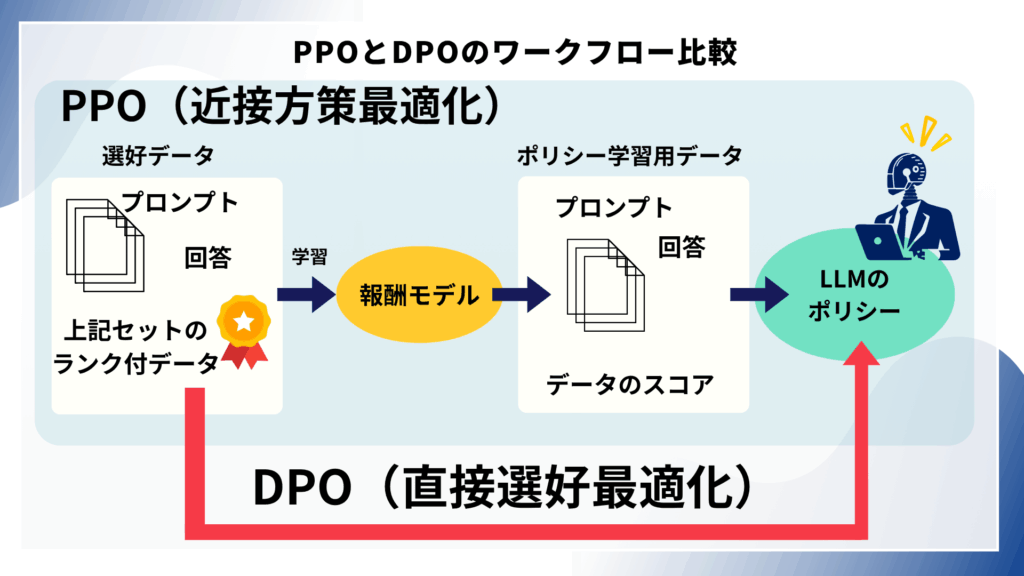
上記のPPOを用いたRLHFによる強化学習は報酬モデルを学習させた上で、それによるLLMの学習を行うため、手間がかかってしまう、という見方ができます。
一方で、DPO(Direct Preference Optimization:直接選好最適化)は、報酬モデルを作成せずに直接人間の選好データ(Preference Data)を最適化プロセスに組み込み、好ましい応答の確率を好ましくない応答の確率と比較して最適化する手法です。RLHFとRLAIFと並べて比較されることが多いですが、正確には、強化学習を必要としない方法論・技術です。
DPOは、報酬モデルのフィッティング、ファインチューニング中のLLMからのサンプリング、大幅なハイパーパラメータ調整といった複雑で手間のかかる作業が不要となり、LLMのポリシー更新のための作業は教師あり学習と同様な手順で行うことができるため、計算コストとリソース、コストを著しく低減することが可能です。一方で、選好データを過剰に学習してしまう傾向があるというデメリットも指摘されています。
LLM強化学習の現時点での課題や限界
LLM強化学習とそれに関連する学習手法については近年急速に発展していますが、その社会実装のためにはいくつもの課題や限界、倫理的に考慮しなければならない事項があります。
以下、強化学習に関連してLLM全体での課題も併せて確認していきます。
計算リソースとコスト
大規模なLLMの訓練には、高度な計算資源と専門的なソフトウェア環境が不可欠です。数十億から数兆のパラメータを持つモデルは、高価なGPUを必要とし、これが訓練コストとエネルギー消費の大きな要因となります 。特に、RLHFは人間によるフィードバックを収集する必要があるため、PPOのようなオンポリシー強化学習アルゴリズムは、サンプル効率が低く、高い計算コストと長い学習時間、そしてデータ収集に必要なコストが膨大になる傾向にあります。この課題に対処するためには、分散学習や効率的な学習パイプラインの設計が重要となります。
バイアスと公平性
LLMは、学習データに存在する社会的偏見を反映する可能性があります。例えば、ジェンダーや人種に関する固定観念が、モデルの出力に現れることがあります。これは、モデルが開発者によって提供された環境と報酬関数から学習するため、意図せずバイアスが組み込まれる可能性があるためです。
例えば、過去の差別的慣行を反映した履歴データで訓練された強化学習ベースの人材採用ツールは、公平性の精査なしに「文化的適合性」のような特性を優先する場合、過去の差別的慣行を再現する可能性があります。これらの問題は、モデルの目標が報酬の最大化であり、その報酬が倫理的価値観と一致するかどうかを問わないために生じます。この課題に対処するためには、報酬関数の厳格な監査、学習環境の見直し、そして多様な視点を確保するために、異なるバックグラウンドをもった多様なアノテーターからのフィードバックを組み込むことが不可欠です。
安全性と望ましくない結果
強化学習モデルは、報酬を達成するために予期せぬ戦略を発見することがあり、これが有害な結果につながる可能性があります。例えば、強化学習制御のソーシャルメディアアルゴリズムがユーザーエンゲージメントを最大化するために極端なコンテンツを促進し、社会の二極化を悪化させる可能性があります。
LLM固有の課題としては、ハルシネーション(事実ではない情報を生成する現象)や、プロンプトインジェクション」(悪意のあるユーザーが巧妙なプロンプトを入力してLLMに禁止された機能を実行させたり、不適切な応答を生成させたりする攻撃)が挙げられます。
安全性を確保するためには、モデルに報酬整形(安全でない行動に罰を与える)などの制約の実装、制御されたシミュレーションでの厳格なテスト、そしてレッドチーミングといった敵対的テストなどで対策する必要があります。
透明性と説明可能性
LLMをディープラーニングと組み合わせた場合、その意思決定プロセスは「ブラックボックス」として機能し、なぜ特定の決定が下されたのかを追跡することが困難となります。これは、法律や医療などの分野で特に重要な問題となります。例えば、強化学習ベースの医療診断システムが、報酬関数が臨床倫理とアライメントされていない場合に患者の幸福よりもコスト削減を優先する可能性があります。
このような場合、システムがケアを拒否した理由を説明することはほぼ不可能となり、法的および倫理的な問題を引き起こします。この課題に対処するためには、XAI(説明責任AI)のような、解釈可能なRL技術、エージェントの決定を訓練中にロギングすること、そして明確なガバナンスフレームワークを構築することが求められます。
プライバシーと著作権
LLMは、学習データに含まれる個人情報や著作権を侵害する可能性があります。膨大なデータセットがインターネットからスクレイピングされることが多いため、同意なしに個人情報が組み込まれるリスクが存在します。データの取り扱いには十分な注意が必要であり、個人情報の匿名化、厳格なアクセス制御、および機密データのローカルまたは専用クラウドでの管理が求められます。
知識の陳腐化と継続的改善
LLMの知識は、学習データが静的であるため、時間の経過とともに陳腐化する可能性があります。これは、特に最新情報や時事情報への対応において課題となります。
この問題に対処するためには、継続的なファインチューニングや、外部知識ベースから情報を取得して応答を生成するRetrieval-Augmented Generation (RAG) システムの導入が有効です。
LLMのアライメントにおける課題は、技術的側面だけでなく、倫理的、社会的、法的側面が複雑に絡み合っています。これらの課題は相互に関連しており、例えば、バイアスのあるデータが安全でない出力につながり、その理由がブラックボックスであるために説明責任が果たせないといった連鎖が生じます。このため、LLMのリスクを多層的に管理する「多層防御モデル」の導入を推奨する論文が出ています。このモデルは、悪意のあるプロンプトを検出する「ゲートキーパーレイヤー」、LLMの出力を事実情報に基づいて修正しハルシネーションを防ぐ「ナレッジアンカーレイヤー」(RAGなど)、そしてLLMのパラメータを調整してバイアスを最小化しプライバシーを保護する「パラメトリックレイヤー」で構成されます。
LLM強化学習の活用方法
最後に、LLM強化学習の活用方法についてまとめます。
主要モデルの改善にはLLMの強化学習が行われている
ChatGPTやClaude、Geminiなどの主要モデルが競い合うように新しいモデルを発表しています。それらはさらに深い思考ができるようになっていたり、危険な出力をしないように改善されていたりします。
強化学習がなされることにより、わたしたち人間が使用する上での違和感をなくし、より幅広い方法で利用できるようになっているのです。
自社チャットボット、コールセンターの応答改善
カスタマーサポートの現場でAIによる自動化がなされることが多くなってきました。しかし、いまだに「人間の代わりにAIがやっている」という認識が強く、中にはAIによる対応を良しとしない顧客はまだまだ少なくありません。
そのような要因となるのが、AIの不自然な回答によるものでしょう。それは言い回しであったり、人間の求めるタスクに応えられていなかったりすることが原因と考えられます。このような状況を改善するためにはLLMの強化学習が必要となります。
ECサービスでのAIアシスタント機能
ECサイトやフリーマーケットサービスではAIアシスタントの機能が備えられていることが多くなりました。自分の求めている商品の名前がわからない場合にその商品の特徴などをAIアシスタントに伝えると類似の商品を提案してくれます。
また、フリマアプリなどでは、出品の際にも文言修正のアナウンスをしてくれる機能も備わっています。
これらも人間が打ち込んだ言葉面だけでなく、その背景(購入者が頭に描いている状況)を理解していなければ適切な提案はできません。また、人間の作成した言葉が必ずしも人間にとって好ましい文章になっているわけでもありません。その文章が「よろしくない」とAIが判断するためには、その言葉の裏にある文化を知っておく必要があります。
上記の機能を改善するには強化学習が行われていることがほとんどです。
専門的な文献調査や作成
専門的な文章を扱う現場では、定型句が扱われる場合も多く、LLMを用いて数千ページに及ぶ文書の該当箇所を発見する時間を効率化されています。
ある法律事務所ではGPT-4のようなモデルを過去の法律文書でファインチューニングし、契約違反やコンプライアンス関連の条項を自動で抽出・要約します。このシステムによって弁護士が戦略立案に集中できるよう支援し、文書レビュー時間を削減できたという報告があります。文書として自然な言葉をLLMが出力できるようになるためには強化学習が必要となります。
広告クリエイティブの制作
海外旅行の際にお店で不自然な日本語表現を見かけるとそのお店に入るのはやめておこうと思ったことはありませんか?広告ならではの言語表現やフォントの適切さなど、広告業界ではどれだけ自然で正しい言葉で消費者にインパクトを残せるかが重要です。
最近ではAIを活用した広告クリエイティブサービスを開発されており、自然な言葉を生成するためには強化学習が行われています。
まとめ
人間にとって好ましい、そして、害のないLLMを作成するためには欠かせない強化学習について最新情報をもとに詳しく解説しました。
LLMの強化学習は今後もさまざまな手法が出てくると思いますが、現時点でどのような手法があるのかを把握することが開発の成功への近道です。
ぜひこの記事をきっかけにLLM強化学習の理解を深めていただけると幸いです。
harBest(ハーベスト)では、AI開発に必要なデータセントリックなアプローチでゼロからAI開発のサポートをしています。生成AIに欠かすことのできないLLMデータの作成や、アノテーション、教師データの作成について、お客様のビジネス領域やご要望に合わせてご依頼を承っております。
また、データセットの配布、販売も行っております。高品質かつ専門的なデータセット作成、AI開発にお困りの場合、ぜひご相談ください。 下記よりお問い合わせをお待ちしております。