【データ不足の時代に必要】合成データについて詳しく解説!

生成AIの利用が一般的になる中で、「AIが学習するための高品質なデータは2026年には枯渇する」という見方が現実的になりつつあります。
その理由として挙げられるのが、高品質なデータは人が手作業で作成、品質確認を行なっているものが多いことからスピーディーに作成するのが難しいのに加え、世の中にある学習データはすでに学習されてしまっているものばかりとなり、成長がストップしてしまうのではないかというものです。
それだけでなく、世の中に存在するデータのうち、銀行や医療などの個人のプライバシーが関わるデータ、企業の秘匿情報などデータの取得が困難であるということが挙げられます。許諾を得ることで使える場合もありますが、その許諾料が高額であることで実際の活用が難しい場合もあります。このような理由から、盛り上がりを見せるAIもデータ不足により成長がストップしてしまう危機に瀕しているのが現状です。
本記事では、このような状況で質の良いデータのニーズが高まる中、スピーディーにデータを作成でき、ニーズに合わせ膨大なデータを作成できることで注目されている、合成データについて詳しく解説します。
目次
合成データとは?

合成データとは、実際に存在するデータを模倣することにより作られた人工的なデータです。コンピュータアルゴリズムによって現実にある実データに近いデータを作成するものです。近年のデータの不足を補うために使われることが多くなってきています。
合成データは、相関性、統計量を残すことで元の実際のデータに似せながら新しく作成されたデータであるため、実際のリアルなデータではありません。それにより、プライバシーの保護ができるだけでなく、元データと変わらない一定以上の質を残すことができます。
そのため、膨大なデータが必要でありながら、実際のデータに寄せたデータが求められていたAI機械学習モデルの構築や分析で活用することが容易になるという利点があります。
なぜ合成データが使われるのか?
労働人口の減少により、生成AIや個社ごとに独自のモデル開発を行って自社の業務効率化/合理化、DXを図りたいと考えている企業は多くなっていますが、莫大なコストだけでなく、そもそもデータの整理などの作業を行う人手が足りず結局実行できずにいるという企業が多いのが実情です。
また、その前段階として、未だに紙で保管されているデータが多くデジタルデータ化されていない、または、学習に必要なデータを持ち合わせていないためデータの作成が必要になる場合など、データ活用においてもボトルネックになってしまっている場合も散見されます。

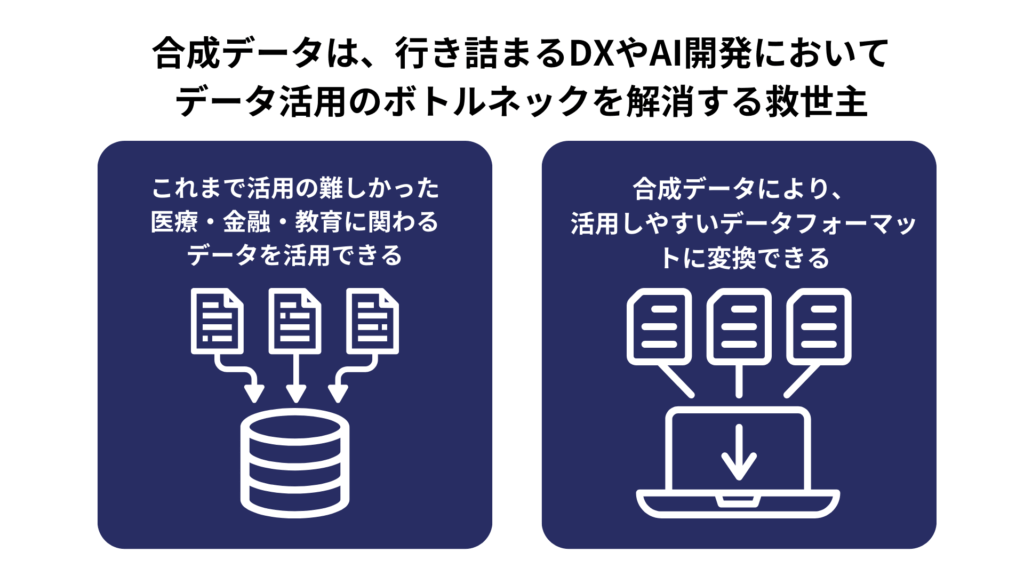
さらに、データ活用のボトルネックとなってしまっているのは、前章でも述べた通り、医療、銀行、教育などの個人に紐づく、プライバシーに関わるデータが個人情報保護の観点によりデータとしての利活用が進みづらい現状にあります。
こうした状況において、プライバシーや法、所有権など様々な制限がある中で、合成データにより、実際のデータに近い人工的に作られたデータを作成できることで、モデルの学習や分析にデータを活用することができます。
合成データは、実際のデータの特性や構造に基づいて合成されるため、統計分析を行った場合、類似した結果を出力することができます。
プライバシーや許諾、法律をしっかりと守りながら同様の結果をもたらしながらデータセットを作成できる点で合成データは大変有用であると言えるでしょう。
合成データの種類は主に2つ
様々なアルゴリズムやモデル、シミュレーションなどを用いて実際のデータに見られるパターンや相関関係、分布を再現します。この場合、人工的に作成され、矛盾が生じてきてしまう可能性があるため、その点を注意して作成する必要があります。
合成データにおいては主に2つの種類があります。
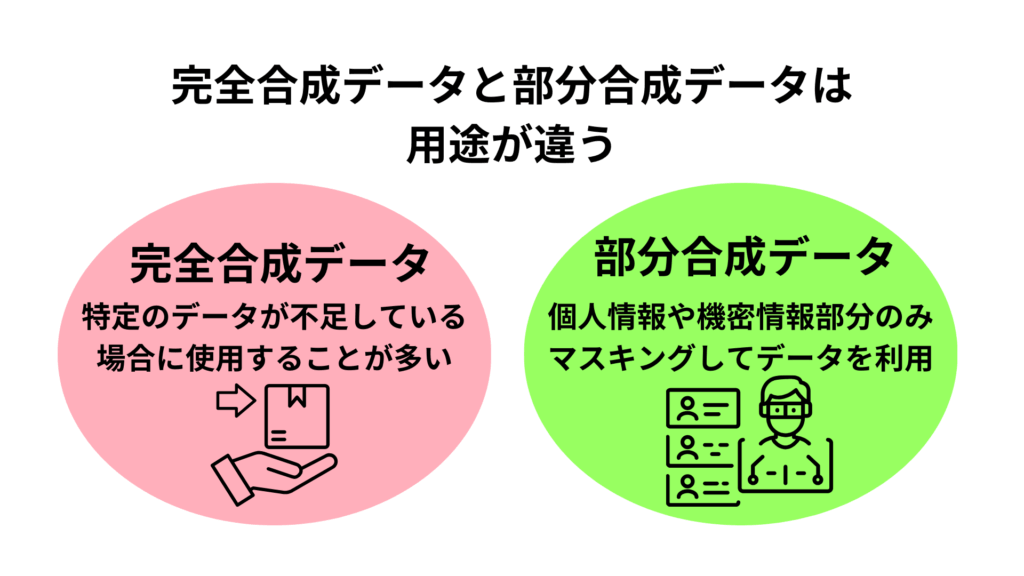
完全合成データ
名前の通り、完全に一から合成されたデータであるため、このデータには実際の元のデータは含まれていません。元の実際のデータ同様のパターン、関係性、統計プロパティ(データや確率分布などの統計的な性質や特徴を表す性質や指標)、プロット分布を使用してデータを作成します。
完全合成データは、特定のデータが不足している場合にそれを補うために作成されるケースに利用されます。
部分合成データ
実際のデータセットの一部を合成情報に置き換えます。部分的であっても合成を加えることにより、実データの特性を活かすことができつつ、データセットの機密部分を保護することができます。
部分合成データは、実データの数値が重要となる場合で、個人情報に繋がる部分のみを合成が加えた方がいい場合に使用される方法です。
合成データはPythonライブラリにあるようなデータを使って作成する方法だけでなく、オープンソースのアルゴリズム、ツール、パッケージ、フレームワークなどを利用して作成することが可能です。
合成データはどのように作成されるのか

合成データを生成する方法には下記のような方法があります。
統計分布に基づく手法
実際の統計分布を観察して分布から数値を導き出し、類似の事実データを再現します。実際のデータが入手できない状況では、この合成データを活用できます。
このアプローチでは、統計関数を用いることで、データの分布を定義し、その分布からランダムにサンプリングすることで新しいデータポイントを作成します。
GAN(敵対的生成ネットワーク)
ディープラーニングを用いる方法で、2つのニューラルネットワークが作用し合うことで、精度の高い生成が可能となる方法です。
合成データを生成する生成器(ジェネレーター)がデータを生み出した際に、本物かどうかを識別する識別器(ディスクリミネーター)が判断し、生成器にフィードバックを行います。この2つのネットワークによって反復的にトレーニングされることで、精度が高くなり、質の高い合成データを生成することができます。
GANについてはこちらの記事で詳しくまとめていますので併せてご覧ください。
https://harbest.io/documents/1032/
VAE(変分エンコーダー)
GAN同様にディープラーニングを活用する方法で、学習したデータのバリエーションを生成するモデルです。
実データを低次元空間に圧縮するエンコーダーと、圧縮された実データの圧縮表現を分析して新しいデータを再構築するデコーダーを備えた教師なし機械学習モデルの一種。入力データと出力データが類似するように合成データが生成されます。
ディープラーニングを用いたトランスフォーマー
こちらもディープラーニングを用いた方法で、トランスフォーマーは主にSLM(小規模言語モデル)やLLM(大規模言語モデル)の基盤となる技術で、言語の構造やパターン理解に長けています。
データセット内の複雑なパターンや依存関係を学習することで、トランスフォーマーは既存のトレーニングデータに対応する全く新しいデータを生成します。
合成テキストデータや合成表形式の作成に適しているのが、トランスフォーマーを用いた方法です。
エージェントに基づくモデル化
観察された行動に基づくモデルを設計し、同じモデルを用いてランダムなデータを生成します。
複雑なシステムにおいて、個々のエージェントを実体として含む仮想環境としてモデリングし、あらかじめ決められたルールに基づいて動作し、相互に作用します。そのエージェントの行動、挙動をシミュレーションすることで合成データを作成する方法です。
生成AIの活用
生成AIの多様な表現力により、複雑なデータのパターンを再現することが可能です。テキストデータや画像生成で使用される場合が多いでしょう。生成AIモデルの複雑性により、解釈性が低いという懸念があります。
デジタルツイン
コンピュータのシミュレーションで仮想現実世界を再現し、そこで生じるデータを現実世界の合成データとして活用する手法です。リアルタイムで複雑なパターンのデータを生成することが可能で、リアルな世界のシミュレーターのため解釈性が高いというメリットがあります。シミュレーションの設定が難しいという側面もあります。
合成データが活用される理由
費用対効果が高い
リアルなデータは収集に時間がかかるだけでなく、膨大なコストがかかります。個人情報や機密情報が含まれる場合は提供者によるマスキングし処理を行う必要があるなど手間がかかってしまうため、コストが嵩んでしまうケースが多いです。合成データは人工的に作成できるためその分コストを浮かせるだけでなく、実データに近い品質を確保できるためコストパフォーマンスが高いという利点があります。
必要なデータセットをスピーディーに生成できる
ツールなどを用いることでリアルデータを集めるよりも早く作成することができます。また数も膨大に作成することも可能なため、データの数が足りない場合に補うことが可能です。
カスタマイズ可能なため特定のニーズを満たすことができる
作られたデータの利点としては、特定のビジネス領域や用途などのニーズに合わせたデータを作成できる点でしょう。ニーズに合わせたデータ収集は用途に合致したものであるか確認する作業に時間とコストがかかってしまうため、そういった場合に合成データの利点が活きてきます。
データのプライバシー保護ができる
上記で何度も述べてきた通り、合成データの一番の利点としてはこれまで個人情報や機密情報により活用が制限されてきたデータが、そのような部分だけデータを差し替えて利用できる点にあります。合成データで人工的に作られることにより、プライバシーの保護、機密情報保護をしつつデータを活用できるという点が一番の利点と言えるでしょう。
合成データの活用方法
合成データが使用される代表的な業界にはこれまでも挙げたような医療、教育、金融など個人、機密情報が多い現場があります。個人と結びつきの強いマーケティングにも活用されています。
それ以外にも、物流業界では、無数のモノを取り扱う関係上、配送センター・物流センターで使用される作業ロボットがモノの形を検出し、障害物にぶつからないようにするためのデータの作成と学習には膨大なデータが必要となります。
さらに、膨大な数の実データの取得が難しい自動車業界の自動検知システムの学習のための衝突データや製造業における欠陥品データや基準となるものから逸脱しているもののデータ生成にも使用されています。
合成データの使用範囲は上記に挙げたものだけでなく、膨大なデータを使用して学習する場合には検討されることになるでしょう。ここではどういった場合に活用されるかという観点から代表的な4つをまとめて言及したいと思います。
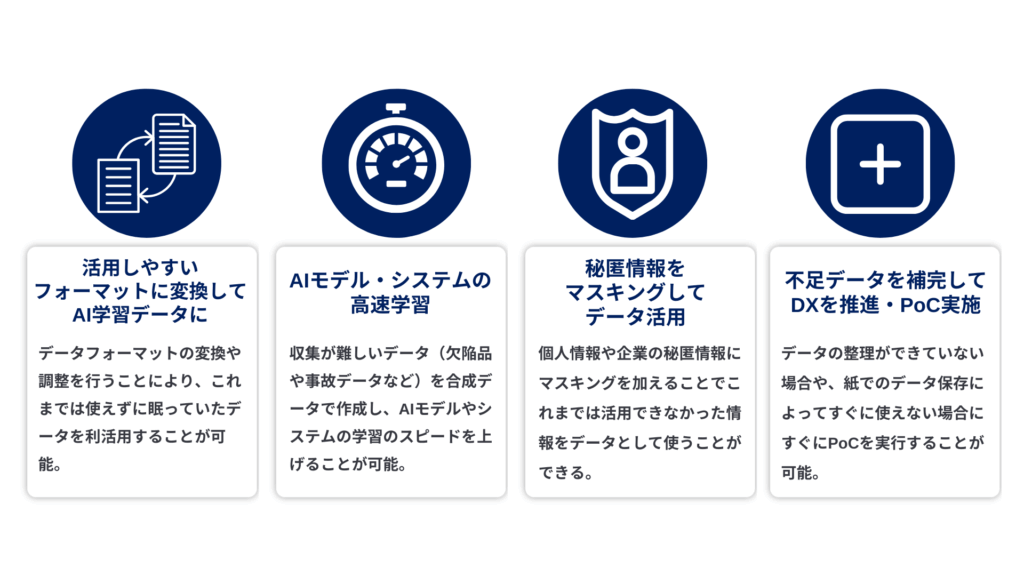
活用しやすいデータフォーマットに変換しAIの学習データに
個人情報や企業の機密情報など、データフォーマットの変換や調整を行うことにより、これまでは使えずに眠っていたデータを利活用することができます。それにより、金融、教育、医療などの業界の現場でAIの活用が広がることが期待できます。
AIモデル・システムの高速学習
欠陥品や、事故データなどのデータは数が少ないことから(多くあったらそれはそれで問題ですよね)、合成データによりデータ数を増やすことで学習を進め、品質管理や検査を行うシステムモデルの精度を上げることができます。
個人情報や秘匿データマスキングによるデータ活用
マスキングを施すことで、医療データなどの患者のプライバシーを損なわずに医療データとしてのみ学習を進めることで医療機器の性能の向上に資することができます。また、製造、物流、教育などの現場でも同様に個人情報を隠した状態でデータを活用できるため、データを活用するサービスの拡大につながるでしょう。
不足しているデータの補完によるPoC 、データを活用したアジャイルなDX
DXが叫ばれて久しいですが、労働人口が減少している日本ではどんな企業でもデータの整理を行う人員が確保できないことにより何もできないままほったらかしである場合や、中小企業や企業としての歴史が浅い場合は蓄積されているデータ自体が少ないという現状があるでしょう。
その場合は合成データを利用することで、すぐにPoCを実施することができ、データの整理ができていない状態でも仮想的にデータを作り出し、活用できるという利点もあるでしょう。
生成AIと合成データの使い分け方法
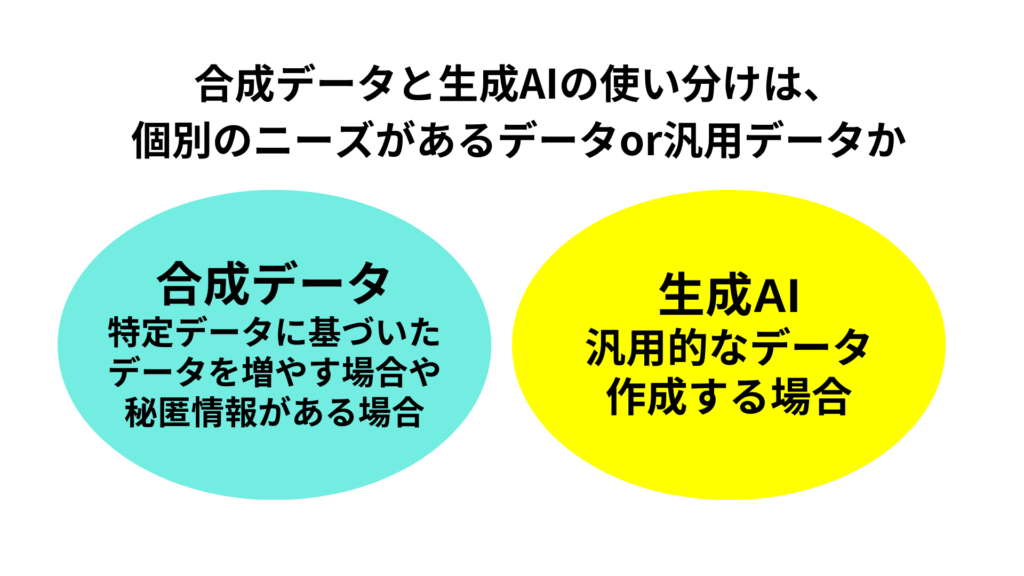
ここまで合成データについて述べてきましたが、合成データと生成AIでのデータ生成での違いがいまいちわかりづらいと思います。
その大きな違いは、個別のデータ作成に適しているか、汎用データに適しているかの違いです。
合成データはある特定のニーズで求められるデータセットの作成においてリアルなデータと同じ構造を持ちながら個人情報などを置き換えて利用できるものです。一方、生成AIはプロンプトに応じてニッチな作業が可能になっていますが、基本的には汎用型のAIであるため、個別のケースのデータ生成には向いていないことがあります。
リアルなデータの置き換えとして合成データの活用を検討するというのが自然な流れと言えるでしょう。
合成データの課題
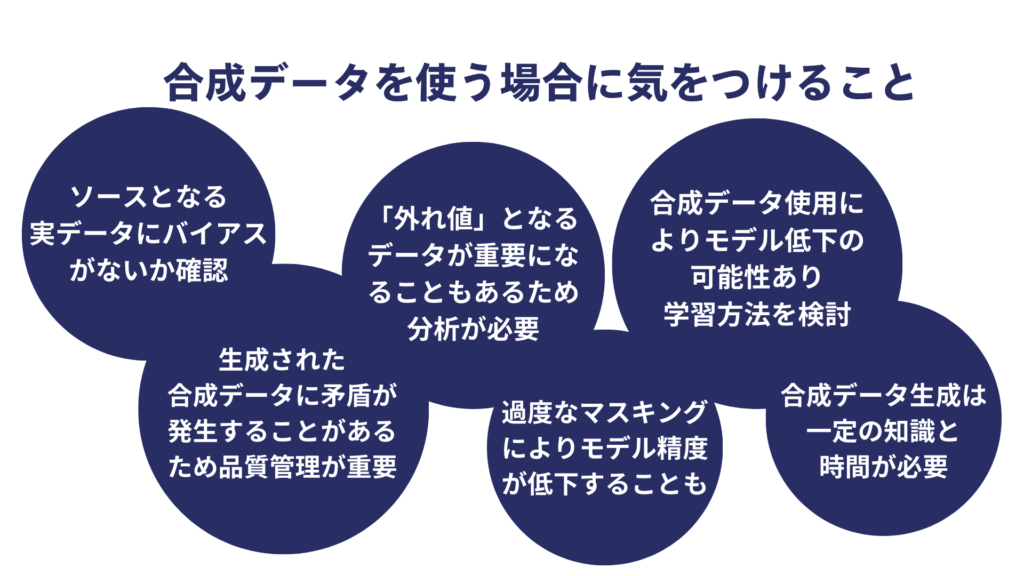
データの信頼性とデータのバイアス
AIモデルの性能は、モデルではなく多くの場合学習データの品質に影響されることが近年の常識となりつつあります。
この合成データにおいてもソースデータにバイアス(偏り)がないことを確認することが重要です。合成データにバイアスが反映されないよう検証、確認が必要となります。
品質チェックとデータ出力の管理が必要
学習モデルに組み込む前に作成された合成データの品質のチェックが重要となります。あくまでも合成で作られたデータのため、品質が本物のデータに劣ってしまっている可能性があります。整合性が取れていないなどのデータ自体、データ間での矛盾が生じてくる可能性があります。
合成データの使用には品質管理が最も重要となるでしょう。
外れ値が重要になることも
現実世界のデータには必ず合理性とはかけ離れた「外れ値」のデータがあります。どんなに専門知識があっても現実世界を完全に模倣できる合成データの作成は難しいです。その外れ値が重要になるケースもあるため、外れ値の分析を行い、合成データを作成する必要もあるでしょう。
プライバシーの保護とモデルの精度の塩梅が重要(トレードオフ)
プライバシーの保護ができる点が合成データの利点である一方で、プライバシーを重視し過ぎてしまうと、モデルの精度に影響が出てしまう可能性もあります。
その場合、データセットのどこにマスキングや合成データでの置き換えを行うのか調整する必要があります。合成データのユースケースに応じて適切なバランスを見つけることが重要です。
合成データの作成には一定の専門知識、労力が必要
合成データの作成には手法やデータ規則などのかなりの知識が必要となるため、正確性と有用性を確保するためには、高度な専門知識を持つ専門家やデータ作成専門企業に依頼する方が良いでしょう。
モデルの性能の低下を防ぐ対策が必要
正確性の低いデータは間違った回答を生成したり、AIモデルの性能の低下を招いたりする可能性があるため、そもそも合成データを使用するべきなのか、リアルなデータと組み合わせるべきなのかを判断して学習に使用する必要があります。
まとめ
今回は、生成AIの輝かしい活躍の裏で、実は注目されている技術の合成データについて解説しました。合成データは、これまで活用できていなかったデータだけでなく、不足しているデータを作成できることで開発やDXのスピードを上げることが期待できます。
harBest(ハーベスト)では、機械学習モデル構築に必要なデータの作成、合成データの作成だけでなく、生成AIに欠かすことのできないLLMデータの作成や、アノテーション、教師データの作成について、お客様のビジネス領域や要望に合わせてご依頼を承っております。また、データセットの配布、販売も行っております。高品質かつ専門的なデータセット作成にお困りの場合、ぜひご相談ください。 下記よりお気軽にお問い合わせください。