RAG(ラグ・検索拡張生成)とは? 活用事例まで詳しく解説!

ニュースメディアを見ているとAIについての話題は1日に一度は触れられるようになりました。AIにかかわる技術開発スピードが日進月歩であり、多様な業界で活用されるようになった証ですね。
ChatGPTなどの生成AIを使用している際に、「最新の情報が出てこないから微妙な回答になっている」と感じることはないでしょうか?
または、「あるサービスのチャットボットの情報が古くて全然参考にならない」と感じたことはないでしょうか。
これはいずれも、LLMの学習したデータが過去のある期間までであるために、生成AIは最新の情報について回答することができず、「ちょっと時代遅れの回答」をしてしまうことがあるのです。
今回は、LLMのハルシネーションを抑制し、最新の情報を参照できる効果が期待されるRAGという技術について詳しく解説します!
目次
RAG(ラグ)とは?
最近生成AIの文脈でよく聞くようになったRAGですが、「ラグ」と読みます。
Patrick Lewis氏の2020年の論文で初めて言及された比較的新しい概念で、Retrieval-Augmented Generationを訳して日本語では「検索拡張生成」「取得拡張生成」などと訳されます。
RAGの特徴は、内部リソースと外部リソースを組み合わせることでユーザーが求めていることを裏付けのある情報と共に回答できるため、生成AIの情報に信憑性が生まれるとともに、企業のセキュリティを守りながら生成AIが利用できるという点でしょう。
LLM(大規模言語モデル)の課題に対応するRAG
LLMは、インターネットなどから収集した学習済みのデータの中から、提示されたプロンプトに対して、ある言葉の次に続く可能性の高い言葉を予測・分析して並べ、文章を作成しています。
これまでLLM(大規模言語モデル)の課題として、過去のある時点までの限られた範囲しか学習していない(GPT-4の場合は2023年4月までというように現在まで学習しているわけではない)ことによって、アップデートされていない情報が回答として出てきてしまうだけでなく、金融情報や社会情勢などの変化の大きい事柄に対して質問された場合などにもっともらしくウソをついてしまうハルシネーションなどが挙げられてきました。
それを解決するための一つの技術としてRAGが注目されるようになりました。
LLM(大規模言語モデル)の精度を高める方法
RAG以外にも知識の拡充などによりLLMの精度を高める代表的な方法がいくつか存在します。
継続事前学習
すでに事前学習をしている言語モデルに追加して事前学習をさせることで精度を上げるという基本的な方法です。新しいデータを継続的に学習することで、新しい環境に対応できるようになります。しかし、学習には時間がかかってしまいます。
ファインチューニング
LLMの多くはインターネットなどの情報を学習しているため、汎用的な知識が事前学習されています。それに加えて、新たな層を追加することで再学習させ、専門的知識を拡充し精度の高い結果を得ることにつなげます。特化させたい領域の学習を行う際などに用いられます。これはモデルを再利用する形になるため、短時間で行うことができるというメリットがあります。
プロンプトエンジニアリング
上記2つの方法とは視点が変わりますが、精度の高い結果を引き出すためには、目的の出力を生成させるプロセス、すなわち、入力する指示を精度の高いものにしなければなりません。プロンプトエンジニアリングには命令、背景・文脈、入力(処理してほしいデータや質問)、出力形式の大きく分けて4つの要素があり、実行するタスクによって工夫することで求める回答の精度を高くすることができます。
継続事前学習やファインチューニングでは、新たに学習させる必要があり、クローズドな情報はセキュリティ上の理由によって学習させられないケースがあります。その解決策として、生成AIモデル自体には手を加えず、外部の情報と連携させてLLMの欠点を補う方法としてRAGという技術が注目されているのです。
RAGはどのような仕組みなの?
複雑に聞こえるRAGという技術ですが、意外とシンプルな構造をしています。
大きく分けて二つのフェーズがあります。
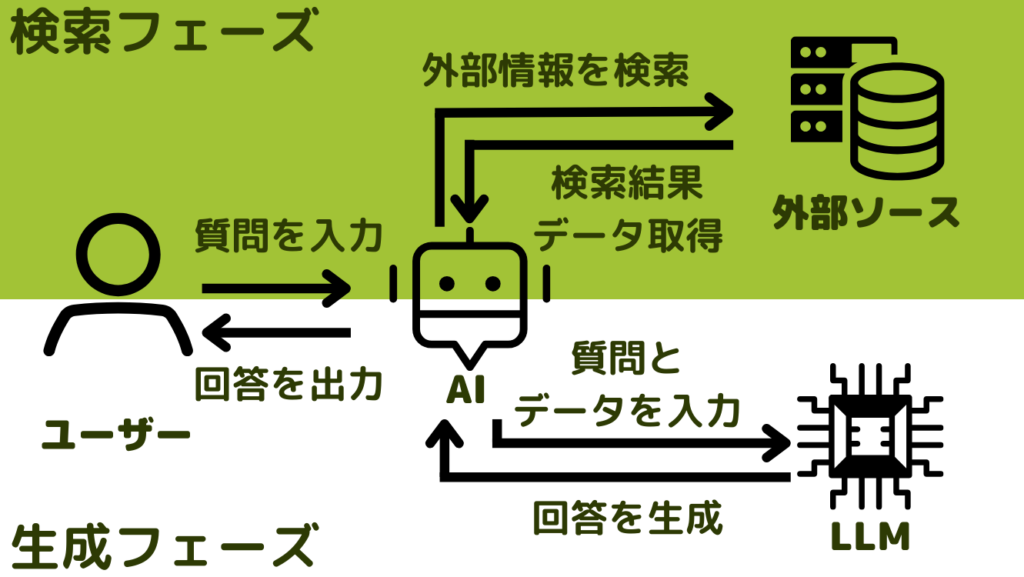
検索フェーズ(Retrieval Phase)
ユーザーの質問に対して最適な回答が作成できるように外部情報を検索してデータを収集します。
①ユーザーが生成AIに質問(プロンプト)を入力
②生成AIが外部情報を検索して質問に適したデータを収集
③検索結果のデータを取得
生成フェーズ(Generation Phase)
生成フェーズでは検索フェーズで得たデータをもとにLLMが回答を生成します。
④ユーザーの質問と検索結果のデータを組み合わせて生成AIがプロンプトを作成
⑤データをもとに、LLMが回答を生成し、チャットAIに返答
⑥生成AIがLLMから取得した回答をユーザーに出力
この上記の流れでユーザーが回答を得ることができます。
RAGのデータベース上での検索方法
RAGが検索する方法は主に4つに分けられます。
①キーワード検索
普段私たちがインターネット検索をする動作のように、キーワードで検索しています。単語や文字列のパターンから類似度に応じて情報を見つけ出します。
②ベクトル検索
単語や文章の意味を捉えて、テキストデータを数値ベクトルとして表現して、ベクトル間の類似度を計算して関連する情報を見つける方法です。ベクトル検索はRAGで自社情報を検索する方法としてよく採用されています。
③ハイブリッド検索
キーワード検索とベクトル検索を組み合わせたものがハイブリッド検索と言われています。ベクトル検索は開発コストが一般的に高くなってしまったり、キーワード検索はデータ量が増えると生成速度が低下してしまったりするため、多くの場合、それぞれのデメリットを補うハイブリッド検索が実装されることが多いです。
④セマンティック検索
検索エンジンが単純なキーワードの一致検索だけではなく、ユーザーの意図やクエリ(データ検索の処理を求める命令文のこと)の意味を理解して、関連性の高い情報を提供するための技術です。自然言語処理やAIの技術により曖昧な表現であっても文脈や意味に基づいて関連性を判断します。
RAGの基本的な構造と仕組みについて解説いたしました。
RAGは比較的簡単に導入できるため、追加のデータセットを使用してモデルを再トレーニングするよりも高速かつ低コストでハルシネーションのリスクを低減し、精度の高い回答を出力することができるようになります。
RAGがどのように活用されているか?
RAGがどのようなケースに活用されているのか、代表的なユースケースを挙げていきます。
カスタマーサポート・チャットボット
あるサービスを利用するとき、わからないことがある場合はまずはよくある質問を確認することが多いでしょう。電話番号があればその電話を繋いでオペレーターと話した方がすぐ解決できるかもしれません。
最近ではカスタマーサポートセンターの電話の待ち時間が長いために、チャットボットを設けて手軽に「よくある質問」以上のことを知ることができるようにしているサービスが増えてきました。
しかし、チャットボットでは回答が「よくある質問」を参照しているだけのものが多く、そのページに誘導されることもしばしばあります。
LLMとRAGを使用することで、チャットの向こう側に人がいるかのような応答を実現するだけでなく、オペレーターでないと確認できないような細かな情報や、今世の中で起こっている変化に合わせた回答ができるようになります。
また、土日祝日なども応対ができるようになるため、企業・利用者相互にとって、休業日も対応ができるというメリットがあります。
これまでオペレーターがマニュアルなどの確認で探していた情報が一瞬で応答できるようになり、業務時間の短縮を可能にします。それだけでなく、業務の習熟度に関わらず、オペレーター・カスタマーサポートの品質を一定値まで高めることができ、人的リスクを低減させることが可能です。
台風や気象条件などで左右されてしまう旅行会社や刻一刻と変わる経済状況に対応する金融サービスでの活用が見込めるでしょう。
情報検索・ナレッジマネジメント
社内には様々な情報が飛び交い、それに追いつくだけで一日が終わってしまう、そんなことはありませんか?日々メールで添付されるプレゼン資料なども確認する暇なく会議に参加しなければならないということもあるでしょう。
これまではデータベースでファイルを探し、その中から求める資料を探し出し、資料の中のどこかから情報を探すという3重の手間がありました。それだけでなく、結局そこには探している情報がなく、他の資料も漁らないといけないという見えない仕事が発生していました。
RAGを使うことで探しているものを直接探してくれるだけでなく、全体把握のために要約までしてくれます。
プレゼン資料・書類作成の効率化
情報検索は何かの書類や資料を作成するためにすることが多いのではないでしょうか。
一日の業務が資料作成で終わってしまうビジネスマンの数は計り知れません。
資料を作るためには情報収集だけでなく、分析も欠かせません。外部データベースとしてこれまでの社内に蓄積された情報だけでなく、市場の状況なども鑑みて分析のサポートをしてもらうことが可能になります。
それだけでなく、分析後のレポート・資料までまとめられるので、これまでの資料作成の時間を大幅に短縮し、プレゼンの練習やその他の業務に時間を充てることができるようになるでしょう。
企業独自コンテンツの生成が容易に
生成AIとはいえ、全くゼロの状況からものを創造することはできません。だからこそ「創造AI」とはいわれることはありません。
生成AIは学習済みのデータからコンテンツを作成しています。そのため、まだ世に出ていない企業の新商品の資料・顧客分析レポートは作成することは不可能です。
社内データベースに接続することにより、それらの生成が可能となります。これはRAGでなければ実現する事はできません。
同様に、社内でしか共有されない企業のこれまでの事例を発信するためにオウンドメディア用のコンテンツを作ることが可能になります。
過去の成功事例を対外的に発信する際に、担当者の議事録や技術者レポートを参照できれば、関わった人たちのインタビューだけでない情報を引き出すことも可能となります。
RAGのメリット
ここまで、RAGの特徴と共にメリットも述べてきましたが、改めてこちらで整理しましょう。
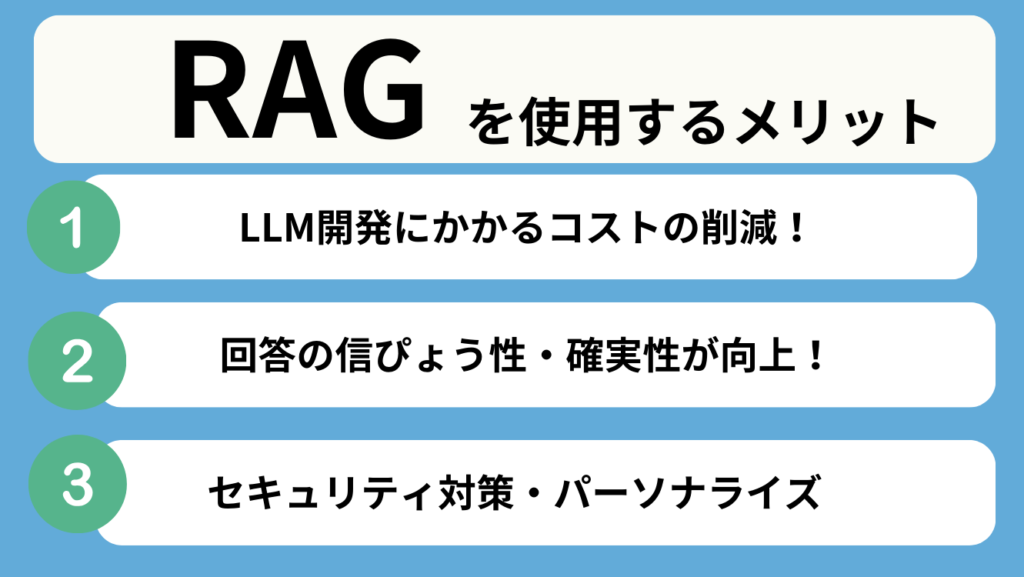
LLM開発にかかるコストパフォーマンスが向上する
簡単に外部データベースにアクセスができるようになるため、再学習よりも手っ取り早く最新情報をもとに回答を生成できるようになります。
ファインチューニングや再学習のためには、データセットの準備や環境構築、実装後の評価改善を行うなどやるべきことがたくさんあるため、コストがかかってしまいます。
RAGを利用することにより、コストを大幅に抑えられるだけでなく、ファインチューニングよりもハルシネーションが起こる可能性を低くできるとも考えられています。
生成結果の信憑性・確実性が向上する
繰り返し述べてきましたが、LLMのみでは学習内容が古いために、ハルシネーションが起こる可能性があります。また、現在の情報に照らし合わせる作業が増えてしまいます。
RAGにより、常に最新情報を得られるようになるだけでなく、社内情報などの正確な外部情報を参照できるため、信憑性の高い情報を出力することができるようになります。
セキュリティ対策ができる・パーソナライズされた回答が生成可能に
LLMに社内情報を学習させることによって安全性が確保されないということが長らく訴えられてきました。
しかし、RAGを利用することで、学習させる必要がなく、外部情報に直接アクセスすることができるようになるため、社外秘の情報であっても簡単に取り出せるようになるというメリットがあります。
これによりLLMの要約力を活かしつつ、パーソナライズされた出力を行うことができるようになります。
RAGを使用する際に気を付けるべきことは?
LLMの弱点を補うため、すべてを解決できそうな気もしますが、もちろんRAGを使用するときには気を付けるべきことがいくつかあります。
独自性の高いコンテンツの生成には向いていない
繰り返しお伝えしてきましたが、正しいソースを参照することができるようになるのがRAGの強みです。一方で、外部情報にはないコンテンツは作成できないため、独自性の高い(創造性を要する)コンテンツの作成には向いていないということを理解しておきましょう。
外部情報が精度を左右する
RAGは外部情報に依存するため、その外部データベースがしっかり整理されていない場合や誤った情報が含まれていた場合は、出力されるものは誤情報になってしまいます。
社内情報を参照する場合はそちらがきれいに整っていない場合は整理する必要があります。RAGの導入は比較的簡単とはいえ、外部データベースを整える作業に多大なるコストを要してしまう場合があります。
機密情報の取り扱いにおけるセキュリティ対策が必要
上記同様に、外部情報がすべてであるため、そのAIにアクセスできる人は簡単に情報を利用することが出来てしまいます。
RAG環境を構築する際は、外部情報にアクセスできる人を制限するなどのセキュリティ確保は欠かせません。
まとめ
LLMとRAGを活用することで、情報の精度向上だけでなく、これまで課題であった即時性・適時性のある情報とともに回答を生成することができるようになることがお分かりいただけたと思います。
一方で、それぞれの技術にはいまだ正確性などの面では課題もあるため、LLMに対して追加で学習を行ったり、ファインチューニングを施したり、RAG自体データ整備なども何重にも対策していくことが必要となるでしょう。
RAG技術に関する資料を無料で公開!
ここまでRAG技術について簡単に記事にまとめてきました。
弊社では、現在RAGに関する詳しい資料を無料で提供しています。
上記のページをご確認いただき、資料をダウンロードいただきました方には、弊社のエキスパートによる無料相談も随時受付中です。
その他お問い合わせは下記のフォームからお問合せください。