フィジカルAIとは?VLAモデル・世界モデルCosmosについても詳しく紹介!

「AIは新たな時代を迎える」と毎年のように言われ、ずっと情報を追っていなければ「何が新しいのか、何がすごいのか」が正直わからないよ、という方もいらっしゃるかもしれません。
一般的に言われるような近年のAIブームの流れを整理すると、2010年代には、画像認識を軸にした、知覚型AIが流行した時期でした。そして2023年終わり頃〜2024年はChatGPTなどに代表されるような「生成AI元年」と呼ばれ、2025年は「AIエージェント元年」、そして今年2026年は「フィジカルAI元年」と移り変わって来ました。
数年前までは、認識専用のAIが主流でした。その後、テキストや画像を生成することで世界を驚かせた生成AIの熱狂は、デジタル空間に閉じた情報の処理から、現実の物理世界で行動を生み出すフィジカルAIへとその中心を移しているというような状況といえます。
現実の物理世界で認識・行動を生み出せるという点で注目されているフィジカルAIは、なぜそこまで注目されているのか。
今回の記事では、フィジカルAIについて概観を解説いたします。この記事をきっかけにフィジカルAIへの理解を深めていただけると幸いです。ぜひ最後までご覧ください。

目次
AIは前提条件になった
一般的によく見落とされている視点でありながら重要なのは、2026年はAIを搭載する、そして、AIを使いこなすのが前提であるということです。
何かプロダクトを作る際にAIをどう使うのかはすでに当たり前の時代になっています。今から新しいものを作ろうとする場合は、AIを念頭に置きつつ、プロダクトがどう他のものとつながっていくか、プラットフォームとしてどう機能するのかを重視しなくてはなりません。
なぜ今、フィジカルAIなのか:AIのパラダイムシフト

冒頭で申し上げた通り、AIは下記の図のようにパラダイムシフトしてきました。
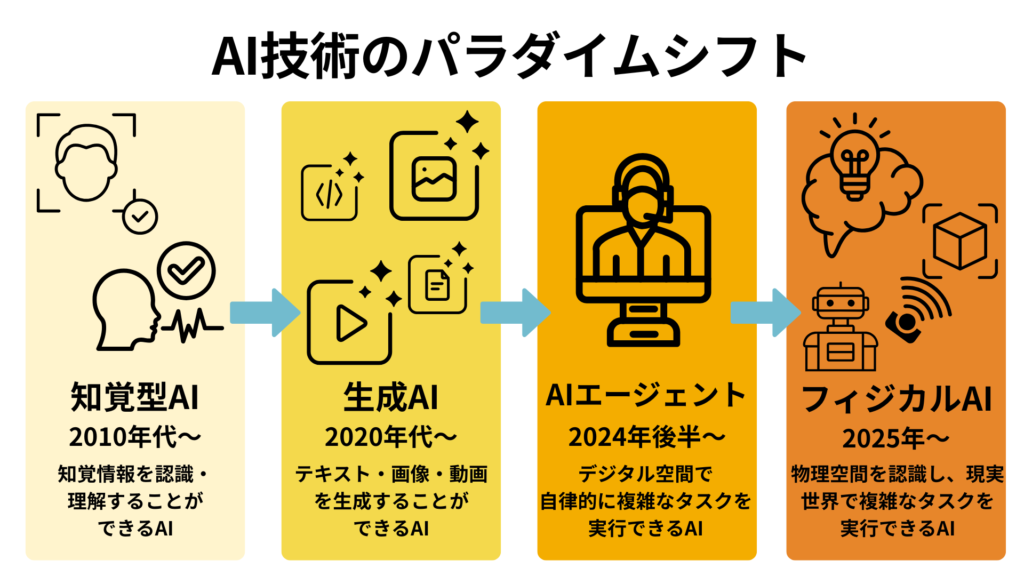
「フィジカルAI」とは、デジタル空間のAIと物理空間のロボティクスが高度に融合したシステムを指すAIです。
従来のデジタル空間で完結していたAIですが、フィジカルAIはカメラやセンサーを通じて物理的な世界を認識・理解し、ロボットアームや車輪、ドローンなどのアクチュエータを通じて物理的に作用します。
このように様々なアクチェータ(現実世界で物理的に動くモノ)が想定されますが、本記事では断りがない場合は「ロボット」として話を進めます。
従来のロボットは、事前に定義されたプログラム通りに動く決定論的な制御に依存していた一方で、フィジカルAIは環境をリアルタイムで認識し、自律的に判断・学習する確率論的なアプローチを採用しています。
人間も普段は無意識/意識的に判断をする際に、「こうした方がいいかも」という選択肢を選び生活をしています。それと同様のアプローチを採用しているのがフィジカルAIであるといえます。
フィジカルAIがこのアプローチを取れるようになった背景としては、複数の技術的要因が絡み合っています。
特に、言語/視覚/行動を統合するVLA(Vision-Language-Action)モデルの成熟、NVIDIA社のCosmosに代表されるような物理法則をシミュレーション内で再現する世界モデル(World Models)の登場、そしてハードウェアの低価格化といった要因が大きいです。
フィジカルAIについてはこちらをチェック
「フィジカルAI以後」はどうなるの?
AIの進化について説明しましたが、「ではAIはどこに向かうのか」という疑問が生まれてくるかもしれません。
多くの大手AI企業は、AIが人間のような汎用知能を得て「人間同等」になるAGI(Artificial General Intelligence:汎用人工知能)を一つの目標としています。さらにその先には、人間をはるかに上回るような超知能を持つASI(Artificial Superintelligence:人工超知能)を見据えています。
実際にこれらはまだ実現はしていないものの、フィジカルAIの発達でAIがついに身体性を獲得したことにより、人間の代わりを果たすことができるのではないかという期待感が醸成されています。
経済界では、物理的なハルシネーション(誤作動)のリスクは伴うものの、製造や物流現場における深刻な労働力不足の解消という明確な投資対効果(ROI)が、フィジカルAI導入の決断を後押ししています。
フィジカルAIの技術的中核となるVLAモデル
フィジカルAIの進化を支える核心技術がVLA (Vision-Language-Action)モデルです。
これは、視覚情報(Vision)、言語情報(Language)、そしてロボットの具体的な動作(Action)を単一のニューラルネットワーク内に統合するマルチモーダル基盤モデルの一種です。
LLM(大規模言語モデル)がテキストトークンの連なりを予測するように、視覚情報(Vision)と言語指示(Language)を入力として受け取り、具体的な物理動作(Action)を出力トークンとして生成します。
マルチモーダルAIとは
マルチモーダルAIとは、異なる種類の情報を一度に扱うことができるAIのことです。すでにChatGPTやGemini などでも実装されているように、音声とテキストから動画をつくることができるのはこれらのサービスがマルチモーダルに対応しているからです。
フィジカルAIとその基盤であるVLAモデルにおいては、主にセンサーやカメラなどで視覚情報を得て、テキストや音声による指示を受け取り、具体的な物理動作を生み出すという点で、こちらもマルチモーダルAIと呼ぶことができます。
VLAモデルが解決する従来の課題
従来のロボットシステムでは、物体を認識するビジョン系、言語指示を解釈する推論系、そして関節を動かす制御系が個別に設計され、それらを複雑なソフトウェアパイプラインで結合していました。
例えると、「テーブルの上の赤いカップを片付けて」という指示を実行するために、以下のような厳密なコーディングが必要でした。
しかし、VLAモデルは画像と言語から動作を直接生成するエンドツーエンド(End-to-End:E2E)」学習を可能にし、これにより、人間が「洗濯物を畳んで」といった曖昧な指示を出すだけで、ロボットがその場の状況に合わせて柔軟に判断、動作・行動を生成することができるようになりました。
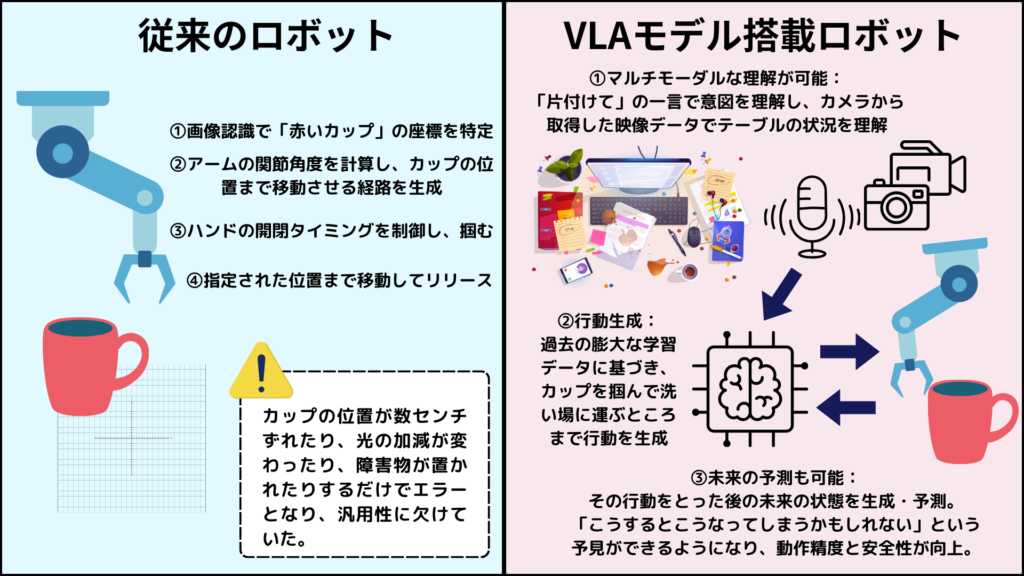
1.画像認識で「赤いカップ」の座標を特定する。
2.アームの関節角度を計算し、カップの位置まで移動させる経路を生成する。
3.ハンドの開閉タイミングを制御する。
4.指定された場所へ移動し、リリースする。
このプロセスは、カップの位置が数センチずれたり、光の加減が変わったり、障害物が置かれたりするだけでエラーとなり、汎用性に欠けていました。
これがVLAモデルにより、下記のようなプロセスに置き換わります。
1.マルチモーダル理解:ロボットは「片付けて」という言葉の意図と、カメラ映像に映る「散らかったテーブル」の状況を統合して理解する。
2.行動の生成:過去の膨大な学習データ(インターネット上の作業動画や、シミュレーション空間での試行錯誤データ)に基づき、「カップを掴んで洗い場へ運ぶ」という一連の動作を直接生成。
3.未来予測:最新の研究では、行動と同時に「その行動をとった後の未来の画像」も生成・予測します。これにより、ロボットは「この角度で掴むとこぼれるかもしれない」といった予見が可能になり、動作の精度と安全性が飛躍的に向上しました。
VLAモデルについてはこちらをチェック
VLMとの違いは?
VLMとVLAモデルは非常に言葉が似ていますが、全く異なるものを指しています。
VLM(Vision-Language Models:視覚言語モデル)とは、画像や動画の視覚情報とテキストを統合して理解・生成するAIモデルです。現在のGPT-4oやGemini3のように、画像の内容を説明したり、図表を読み解いたりすることに長けています。
一方、VLAは、VLMの能力に物理的なアクション(Action)が加わったものです。例えば、VLMが「皿が汚れている」と言語化するまでを担うのに対し、VLAは「皿を洗う」というロボットアームの具体的な動作まで出力します。
つまり、VLMは認識と対話までを担っている知能であり、VLAはそれをロボット制御に応用した実世界で動くための知能であるという点が大きな違いです。
VLAモデルの構造と2つの主要アプローチ
VLAモデルは、視覚エンコーダ、言語エンコーダ、そしてアクションデコーダの3要素から構成されています。2026年現在、開発現場では「統合型」と「デュアルシステム型」の2つの設計思想が競合しています。
最新の研究では、このVLAモデルに「Embodied Chain-of-Thought(ECoT: 身体的思考の連鎖)」を導入する試みが成果を上げています。これは、ロボットが行動を起こす前に、将来の視覚的な状態(サブゴール画像)を予測し、その予測に基づいて行動を計画する手法です。
これにより、従来の直接的なマッピングでは困難だった、複雑な工程を伴う作業の成功率が飛躍的に向上しました。また、モデルのスケーリング則が検証され、700億以上のパラメータを持つ巨大なVLAモデルが、未知のオブジェクトに対する驚異的な汎化能力を示すことも報告されています。
世界モデル(ワールドモデル):現実で起こらないことを生成・シミュレーションする
フィジカルAIを支えているのはVLAモデルという基盤であると前章で述べてきました。
ここで再度確認しておきたいのは、AIが発達するためにはデータとシミュレーションが欠かせないということです。
最近フィジカルAIと共によく語られる、世界モデルがフィジカルAIを下支えしているといっても過言ではありません。
フィジカルAIが物理世界で安全に動作するためには、自らの行動が環境にどのような影響を与えるかを予測する能力が必要です。これを実現するのが世界モデル(World Models)です。
NVIDIA社が2025年末から2026年にかけて発表した「Cosmos」は、この領域におけるデファクトスタンダード(事実上の標準)としての地位を固めつつあります。つまり、世界モデルや世界基盤モデルという言葉を使って語られる場合は、NVIDIA社のCosmosが想定されていることが多いでしょう。
世界モデルは、物理特性や空間特性などの現実世界の原理を理解するニューラルネットワークであり、人間が観測したものから未知の展開を予測するように、物理的に正確な未来の映像を生成します。
これにより、現実世界では頻繁に起こらないが重大な事故につながるエッジケースの状況を仮想空間内で無限に生成し、AIを安全に学習させることが可能となりました。
フィジカルAIでもデータ、そしてシミュレーションが肝となる
ここ数年のAIの技術的な進歩の過程を見ていると学習されるデータの量と質、そして強化学習などの学習の方法により、精度が改善されるだけでなく、大きな技術革新が起こりました。
世界モデルの最大の特徴は、「モラベックのパラドックス」の解決に寄与する点にあります。AIにとって高度な数学的推論よりも、1歳児レベルの身体的感覚を得ることの方がはるかに難しいということをモラベックのパラドックスと呼びます。
世界モデルによる大規模なシミュレーション学習によって、頭でっかちだったAIが身体性を手に入れることができるようになりました。
特に「Sim-to-Real(シミュレーションから現実へ:「Sim2Real」)の移行における誤差が、物理学に基づいた正確なビデオ生成技術によって劇的に減少したことは、世界モデルがもたらした大きな成果と言えると思います。
現実では取得が難しいデータを取得・安全にシミュレーションできる
AIの技術的な発展において、最も大きな壁となっていたのは、現実では滅多に起こり得ないことのデータの取得とそれをシミュレーション方法でした。
例えば、安全性向上のための事故検知・予測するためのAIを開発するときに、すでに起こってしまった事故データを学習することはもちろんですが、これまでは、「こういう事故も起こりうる」と想像できていることや、「こういう事故があったけど、これまでに2、3件しか起こったことがない」ためにデータが少ないことで学習データとしては不足してしまうことがありました。
これをロングテール問題と言います。
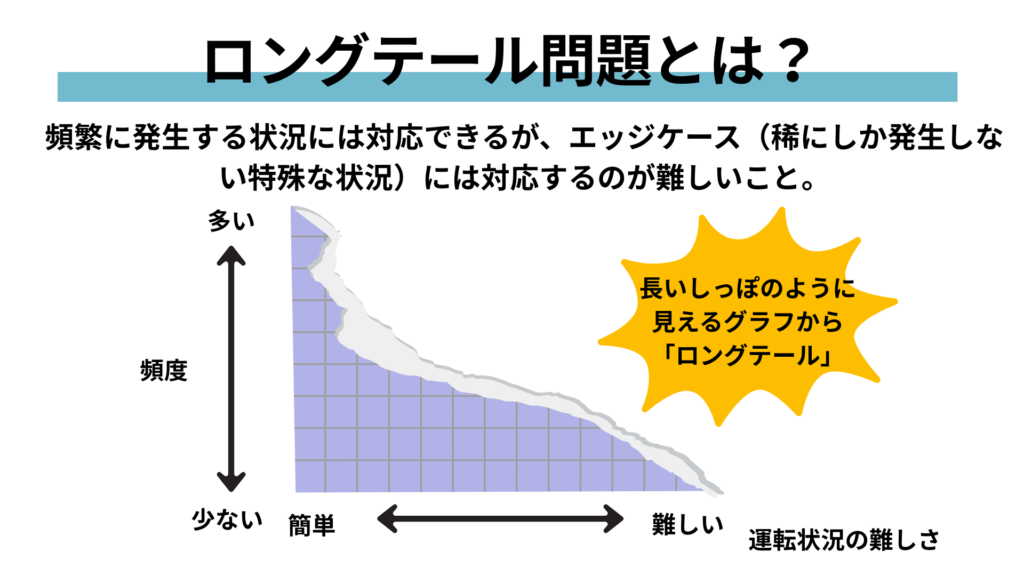
そういった場合に、現実と同じような物理法則を備えた世界モデルでデータを生成し、シミュレーションを行うことで解決できるようになりました。
NVIDIA社が開発した世界モデル「Cosmos」

NVIDIAが発表したCosmosは、フィジカルAIのためのオープンな基盤モデルです。
これにより、開発者は物理的に正確な合成データ(Synthetic Data)を生成し、ロボットに「あり得たかもしれない未来」を学習させることができます。
合成データについてはこちらをチェック
現実世界では危険で試せない衝突事故や機材の落下といったシナリオを、デジタルツイン上で生成・学習させることが可能になりました。
Cosmosでは、プロンプトやシーンの条件から生成を行うだけでなく、そこで生成された行動が次の入力になり、Cosmos内でシミュレーションを回すことができます。
Cosmosの構成
NVIDIA Cosmosプラットフォームは、相互に連携する複数の基盤モデルで構成されています。
Cosmos Predict 2.5:テキストや画像から、物理法則(重力、摩擦、慣性)に基づいた一貫性のある未来の映像をシミュレーション。
Cosmos Transfer 2.5:既存のビデオ構造を保ちつつ、照明や天候、背景をフォトリアルに変換し、多様な学習データ(合成データ)を生成。
Cosmos Reason 2:物理的な因果関係や空間・時間のつながりを理解し、推論を行うVLM。「物体が物理的に正しく動いているか」といった複雑な判断を下します。
Cosmos Tokenizer:高解像度ビデオデータを1/1000以下に圧縮し、AIが高速かつ正確に学習・推論を行えるようにする共通基盤。
詳しくはこちらの資料で解説しています。ぜひダウンロードいただき、ご覧ください。
フィジカルAIで自動運転が変わる!
フィジカルAIを支えているのはVLAモデルであり、そのモデルを強化させていくためには、データが重要、そして、そのデータを生成したり、モデルのシミュレーションを行ったりするのが世界モデルの役割であることをここまで述べてきました。
これらが複合的に絡み合い、2026年に再注目されている話題として、自動運転の新しい姿について解説します。
自動運転についてはこちらをチェック
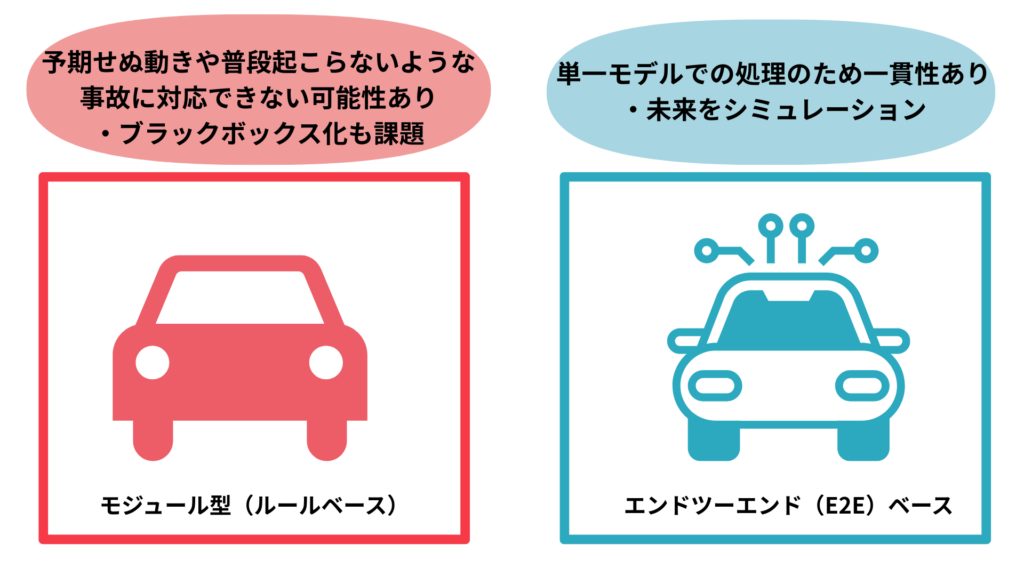
従来の自動運転はルールベース
従来の自動運転(レベル2〜4)は、周囲を認識し、エンジニアが記述した膨大なルールに従って走行するモジュール型(ルールベース)が主流でした。これは前述したように、ほとんどのロボットや機械と同じで、決定論的なアプローチが取られています。
しかし、モジュール型であるがゆえに、予期せぬ歩行者の動きや複雑な交通環境など、ルール化が困難な例外的な事象への対応が大きな壁となっていました。
また、想定外の行動をした際の原因がわからなくなるブラックボックス化が大きな問題となっており、実際に稼働している自動運転車への批判が相次いでいました。
現在の主流はE2E(エンドツーエンド)ベース
最新の仕組みでは、センサー入力から車両操作までを一貫して処理するエンドツーエンド(E2E)方式へと進化しています。つまり、端から端まで単一のモデルで処理を行うものです。
その核となるのは、物理法則や因果関係を把握する世界モデルの導入です。AIは脳内で数秒先の未来をリアルタイムにシミュレーションし、文脈に基づいた柔軟な判断を自ら下すものになっています。
世界モデルはAIにとって「世界」を認知するための環境
人間は本能的に、そして後天的に獲得してきた感覚のおかげで、見るだけで今その状況で何が起こっているかを知覚することができます。
しかし、AIにとってはそういった「世界」の認識が難しいのです。
自動運転車などのフィジカル AI システム向けに世界モデルを構築するには、実世界の広範なデータ、特に多様な地形や条件からの動画や画像だけでなく、起こりうるかもしれない危険な状況でのデータが必要です。
世界モデルは空間的な関係と3D環境における物理的挙動の深い理解により、AIの機能を拡張します。これにより、複雑なシーンで物体がどのように移動し、相互作用するかを予測するなど、現実的な因果シナリオをシミュレーションすることが可能になります。
今年1月に開催された技術の祭典「CES2026」では、NVIDIA社がこの世界モデルを前提にした自動運転向けのオープンソースAIモデルとツール群をAlpamayoとして提供することが大きな話題となりました。
ユースケース:製造・物流から医療、そして、家庭まで
現在でもロボットは様々なシーンで活用されています。工場や倉庫などすでに決まっている繰り返しの定型作業を行うために現場では導入されています。状況に応じた判断が必要なものや、細かい作業が必要なものにおいては人間が担っています。
しかし、フィジカルAIによって、これまで自動化が困難とされていた人間が担っている非定型作業を行うことができるようになると考えられています。
産業界では、主に人材不足とされている分野でフィジカルAIを搭載したロボットが活用されることが期待されています。
物流・製造におけるさらなる自律化
すでに、物流倉庫では、多種多様な形状、硬さ、重さを持つ商品のピッキングや梱包が、VLAモデルを搭載したロボットによって24時間体制で行われています。
Amazonやテスラは、ヒューマノイドを製造ラインに投入し、これまで人間が行っていた複雑な配線作業や部品の仕分けを代替し始めています。Amazonでは物流センターにてコンテナの持ち運びや格納を行うDigitを導入。テスラでは、自社の自動運転(FSD)用ニューラルネットワークを応用したOptimusを自社工場に導入しています。荷物の運搬や簡単な作業を行う労働力としつつ、将来的には工場以外の一般家庭での家事や介護ロボットとしての活用を目指しています。
医療・介護における活用
医療分野では、執刀医の動きを先読みする手術支援ロボットや、院内を自律搬送するロボットの高度化が進んでいます。
介護現場においても、重い患者の車椅子とベッド間の移乗や夜間の見守りをロボットが担うことで、介護職員の負担が軽減されることが期待されています。
家庭における活用
これまでは細かい動作が苦手だったロボットは家庭向けに汎用化するのは困難だと考えられて来ました。しかし、フィジカルAIは、物理空間で自律的に感知・判断・行動し、生活を支える技術となりつつあります。
調理や洗濯物を畳む汎用人型ロボット(ヒューマノイド)、家具の運搬や片付けを担う自律移動ロボットが登場。掃除機のように汚れを識別して自律洗浄するロボットも実用化され始めています。
フィジカルAIの課題とボトルネック
フィジカルAIの可能性は無限大、大きな社会的変化が起こりうると思いますが、もちろん課題もたくさん残されています。
ハードウェアと推論速度の制約
現実世界ではコンマ数秒であっても、その遅延が事故に直結します。高度な推論をエッジデバイス(ロボット本体)でリアルタイムに行うための計算リソースの確保と、物理的な摩耗・故障に耐えうる堅牢なハードウェアの開発が、実用化へのボトルネックとなっています。
シミュレーションと現実の乖離
開発効率を上げるため、Cosmosのような仮想空間(シミュレーター)での学習が不可欠ですが、物理法則を完全に再現することはまだまだ完全とは言えないでしょう。デジタルツインでの開発が進められることは多いですが、その間の乖離により、仮想空間で完璧に動くモデルが照明の変化や物体の個体差などにより、現実の複雑な環境では機能しないという問題が頻発します。
データの「質」と「量」の不足
LLMではインターネット上の膨大なテキストデータで学習がされてきましたが、フィジカルAIは、高品質なマルチモーダルデータが必要です。視覚だけでなく、触覚、力加減、摩擦といった物理的な相互作用データは収集コストが極めて高く、学習に必要な多様性が不足していることが最大の壁となっています。
現在ではロボットオペレーターなど熟練した人間のオペレーターによるデータ生成や、ビデオデータ学習、遠隔でロボットを操縦してデータを記録するテレオペレーション、ロボットの腕を直接動かすキネスティックティーチング、世界モデルを使った合成データの作成など様々なデータ生成方法が取られています。
しかし、データ取得にはコストが高くなってしまうことや、ハード面よりもソフト面、特にデータの不足と質の担保がフィジカルAI開発のボトルネックになっています。
まとめ
今回の記事では、フィジカルAIについて解説いたしました。
フィジカルAIの発達により、ロボティクスにおけるブレイクスルーと技術の一般化が予想されています。
一方で、データの不足により開発が進まないという側面がフィジカルAIの課題となっています。
AIが発達し社会実装されていくためには、AIにとって思考の資源となるためのデータが重要であることは、これからも変わりません。
harBest(ハーベスト)by APTOでは、AI開発に必要なデータセントリックなアプローチでゼロからAI開発のサポートをしています。
AIに欠かすことのできないLLM/SLM/ドメイン特化型モデル開発やフィジカルAIに欠かせないデータの作成や、アノテーションについて、お客様のビジネス領域やご要望に合わせてご依頼を承っております。
また、データセットの配布、販売も行っております。高品質かつ専門的なデータセット作成、AI開発にお困りの場合、ぜひご相談ください。 下記よりお問い合わせをお待ちしております。