【AI時代に欠かせない】データセントリックAIという考え方

AIに関するニュースは連日世間を賑わせています。
先日就任したアメリカのトランプ大統領がAIインフラ事業に今後の4年間で5000億ドル超える巨額な投資を日米共同で行う計画を明らかにするなど、AIビジネスのスピードに拍車がかかることが予想されます。その計画に関わるソフトバンク社は全米にデータセンターとその電力を賄う発電施設を設立する構想を発表し、AI時代においてデータの重要性を改めて世界に向けて発信しました。
日本企業においては、「2025年の崖」という問題が盛んに取り上げられます。国内における企業のレガシーシステムを改変していかなければ、年間で12兆円もの損失が発生してしまうというものです。
AIの導入やAIを活用した新しいビジネスに関しての情報は日々アップデートされています。総務省が昨年発表した「令和6年版情報通信白書」では、生成AIにおいての利用状況はアメリカが46.3%、ドイツが34.6%に対し日本が9.1%に留まり欧米と比較すると低調である一方、「今後の利用には前向き」と答えた割合が7割を超えており潜在的なニーズが高まっていることが示されています。
また、主にLLM(大規模言語モデル)開発にはビッグテックがリードしている中、データの取扱いの透明性や、公平な市場環境の確保、日本の国際競争力強化に向けた対策として、産官学が連携での国産LLMの開発や大量・高品質で安全性の高い日本語中心の学習用データの整備が推進されています。
このように、AI開発や今後のAIを利用した技術・ビジネスの発展が「データ」が中心になっていることがわかります。この考え方が現在では主流となりつつあり、これはデータセントリック(Data Centric)と呼ばれます。
本記事では、AI時代に欠かせないデータセントリックAIという考え方、アプローチについて網羅的に解説します。
目次
データセントリックAI(Data Centric AI :DCAI)とは?
データセントリック、または、データセントリックAI(以下、データセントリックAIと記載します)とは、その名の通り、データを中心に据え、AIシステム、AIモデルの開発を進めるというアプローチ、考え方のことを指します。
データセントリックAIという考え方をより深く理解するためには、従来の主流であったモデルセントリックAIについて見ていきましょう。
モデルセントリックAI(Model Centric AI)とデータセントリックAI

これまではモデルセントリックAIという考え方がAI開発の主流となっていました。つまり、データを固定し、AI機械学習モデルのアルゴリズムやハイパーパラメータの調整などを行い、モデルの改良を行うことでAIの精度を向上させようとする考え方です。
一方、 今回紹介しているデータセントリックAIはモデルを固定し、データの質を高めることでAIの性能を上げていくという考え方です。
これは2021年に開催されたイベント(A Chat with Andrew on MLOps: From Model-centric to Data-centric AI)にて、Google Brainの共同設立者かつ、AI教育のオンラインコースを提供するDeepLearning.AIを率いるAndrew Ngさんが提唱し、AI、機械学習に関わる人々の間で大きな話題となりました。
この背景としては、モデル性能の向上が頭打ちになってきたことも要因の一つです。
もちろん実際のAI開発においてはモデル改良も行われますが、学習させたデータの量や質によってAIの精度が変わってくるということは、今やAI業界においての常識となってきています。
データセントリックAIのメリット
データセントリックAIが開発アプローチの主流となった理由は大きく2つに分けて考えることができるでしょう。
コスト削減と効率化
モデルセントリックAIの場合は、モデルを一から再設計、チューニングを改めて行わなければならないため、時間とそれに比例してコストがかかってきてしまいます。
一方、データセントリックは、データの収集や学習させるデータの質を上げることで改良を行うため、モデルやチューニングを行うよりも時間とコストを抑えることができます。
AIの開発スピードや競合が年々増加しており、AIモデルを開発する企業は変化の早い市場に対応しなければならないため、コストと時間がかからないデータを用いた精度向上を重視するようになってきました。
正確性と信頼性の向上
学習させるデータにバイアスや欠陥が含まれていることでモデルの決定が不正確になる可能性があります。モデルセントリックのアプローチでは、データに内在するバイアスに対処するのが難しいため、データセントリックのアプローチを取ることで、正確性を向上させることが可能となります。
データセントリックのアプローチを取ることで、さまざまなソースからデータを包括的に収集し、データの多様性が保たれるようになり、ハルシネーションの抑制に繋がります。
データセンリックAIのデメリット
データセントリックAIのアプローチは、AIモデルにおいて最も重要であると言える正確性と、人員、金銭的なリソースのコスト削減につながる一方で、データを収集して、ラベリングをしてアノテーションを施すという作業には時間がかかってしまいます。
しかし、モデルセントリックなアプローチと比べると、大幅なコスト削減が望めるため、データセントリックな手法で進めることが多くなっています。
データ収集やアノテーションは社内で行うと、人員と時間がかかってしまい、結果的にコストが増大してしまうため、クラウドソーシングやAIデータを扱う企業に外注を検討すると良いでしょう。
データセントリックAIの考え方を具体的に開発に落とし込むには?
データセントリックの考え方をAI開発に落とし込んでいく方法には以下のようなものがあります。
データの収集とアノテーション作業
データ中心で開発を進めるには、まずはデータの収集から始めなければなりません。社内に蓄積しているデータを使う場合は、データの構造化、整理が必要となります。新たに収集を行う場合は、データの多様性を確保するため、膨大なデータを収集する必要があります。
また、膨大なデータを集めるだけでは必ずしもAIモデルの性能を上げることにつながるわけではありません。アノテーションという、データにラベルをつける作業をして教師データという「正解データ」を作成することで、AIに学習させます。アノテーション作業の正確さもAIの精度に多大なる影響を及ぼすため、精度の高い作業が求められます。
アノテーションに関してはこちら(https://harbest.io/documents/466/)
LLMデータセットについてはこちら(https://harbest.io/documents/559/)
データのクレンジング、クリーニング
最近ではデータを自動的にクリーニングしてノイズを低減したり、実際のデータをもとに合成データを生成したりする技術の発展も注目されています。
データセットの中で特定の属性や特徴量が過剰または不足している場合は、それらを利用して、データの品質を高めるだけでなく、データの多様性やバランスを確保することが可能となります。
データバリデーション
データセットの品質、信頼性を上げるためにも欠かせない工程の中にデータバリデーションがあります。データの品質を評価し、不適切なデータが含まれていないかを確認します。
アノテーションを含むデータ作成においては、データの中での整合性、一貫性、そして再現性が重要であるため、このプロセスを通して、データセットの質が向上し、モデルの性能を向上に繋がります。
HITL(ヒューマンインザループ:Human In The Loop)の考え方

データセントリックAIを語る上では、HITL(ヒューマンインザループ:Human In The Loop)についても外すことはできません。この二つは、データの質を高め、AIモデルを効果的に構築するために相互補完的な役割を果たします。
ヒューマンインザループは、一言で述べると、AI開発において、人間を通してデータを収集、選定、アノテーション、評価を行うことで、AIの精度を向上させるというアプローチ・考え方です。
例えば、英語ではないマイナー言語の文章の作成を行う際、「英語からの直訳で意味はわかるけど、あまり使わない言い回しになってしまっている」という場面に遭遇することがあります。その場合は、ネイティブ話者が文章をチェックし、文章を再構成しなおすことで、より高い品質のデータを作成することができ、AIモデルの品質向上に繋がります。また、専門的な文章である場合は、専門家が作業を行うことでデータの精度を上げることができます。
そのほかにも、自動でアノテーションをしてくれるツールはありますが、人間がラベル付けを行うことで、より細かな作業をして、機械の見落としや曖昧な点を修正することができます。
このように人間がAIトレーニングに使用するデータの偏りを修正し、パラメータの調整やアルゴリズムの改良を行うなど、人間が介在することでAIモデルの性能を上げることに繋がります。
データの質がAI開発に与える影響
最初にあげたA Chat with Andrew on MLOps: From Model-centric to Data-centric AIで示されたデータについて改めて見てみましょう。
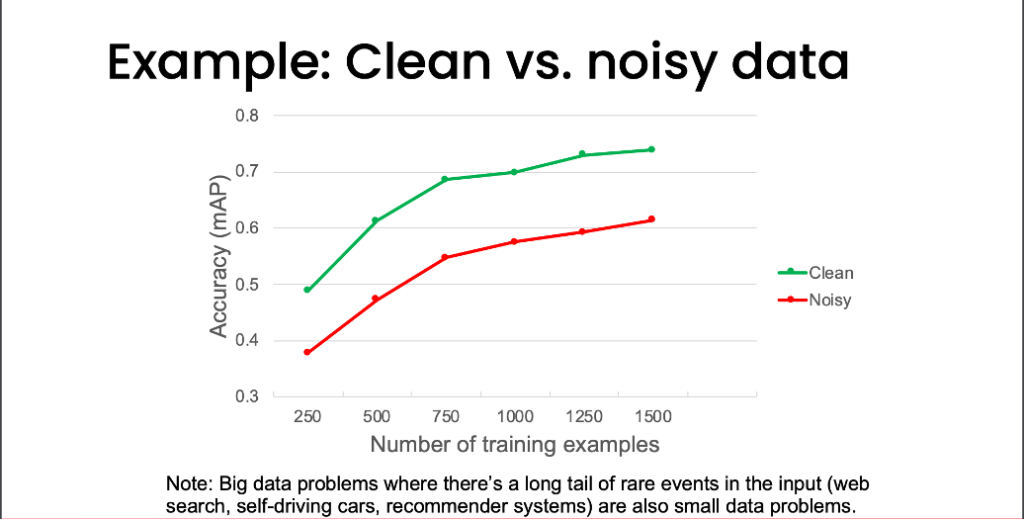
出典:MLOps-From-Model-centric-to-Data-centric-AI
緑のCleanと書かれた線グラフは、データをクリーニングしたデータ、赤のNoisyと書かれた線グラフはノイズが含まれていることを指しています。
縦軸はAIのAccuracy(正解率)、横軸はデータの数についてです。縦軸の0.6mAPを横に見てみるとその違いがわかりやすいでしょう。緑のCleanの線は500個でその正解率を達成しているのにも関わらず、赤のNoisyは1500個ものデータが必要になってしまいます。つまり、データが少なくとも、質の高いデータであれば精度を高くすることが可能なのです。
データセントリックAIは、大量のデータを集める以上に、データの品質を改善することでAIの精度を向上させることができるという考え方が最も大切です。
まとめ
ここまでAI開発において近年では最も重要な考え方となっているデータセントリックAIについて解説しました。
AI開発を試みている企業においては、データが集まらない、データの精度が良くないことにより頓挫してしまうケースが少なくありません。ここで紹介した考え方、アプローチをAI開発に落とし込んでいただけると幸いです。
harBest(ハーベスト)では、AIに欠かすことのできないアノテーション、教師データの作成について、お客様のビジネス領域や要望に合わせてご依頼を承っております。また、データセットの配布、販売も行っております。高品質かつ専門的なデータセット作成にお困りの場合、ぜひご相談ください。 随時ご相談を受け付けております。下記よりお気軽にお問い合わせください。