【精度向上のために】アノテーションのノイズ除去について解説!

近年、企業ではますますAIの活用が促進されており、業務改善や業務効率向上のために導入する企業が増えています。
例えば、製造業やリサイクル業界などでは、機械学習モデルを用いることで、生産ライン上での異常検知、物質の仕分けや、製品の品質管理を行うことで、生産効率の向上や不良品の削減が期待されています。
AI技術が広く活用されるようになってきている中、AI開発において、AIの精度を大きく左右するアノテーションのノイズがAIモデルの性能や信頼性に影響を与える可能性も加味した上での開発が欠かせません。
本記事では、AI分野におけるアノテーションのノイズに焦点を当て、その影響と対処法について解説します。
目次
1.AI開発を進める上で最も重要なこととは?

社内の業務の効率化や、近年DX推進の一端を担うものとして、AIの活用が進められています。
最近の生成AIブームによって、AIは入力するとすべてを解決してくれるような夢の技術と認識されることが多いですが、実際には目的に応じた特定の作業を行うのに適した技術です。
そして企業でAIを開発していくにあたっては、まず社内の現状の課題を明確化し、社内でどのように運用されていくかを検討したのち、必要なデータを収集し、機械学習を行っていくという流れとなります。
AIの精度は、データセットの質の高さに80%以上左右されると言われており、その中にノイズなど機械学習を阻害するものが入っている場合は、AIの結果に悪影響を及ぼす可能性があります。ノイズを少なくするために最も気を付けるべき工程がアノテーションとなります。
2.AI開発にあたってまず知っておきたい言葉
AI開発を進めるにあたって何度も出てくる言葉を紹介します。
まず、アノテーション(annotation)とは、英語の辞書で調べてみると「注釈をつけること」と出てきます。これがAI分野においては「特定のデータに対して情報タグ(メタデータ)を付け加える」という意味になります。
つまり、「教師データを作成する際に、テキストや音声、画像などのデータ情報タグ(メタデータ)を付加する作業」のこととなります。AIの機械学習においてデータ収集した後、データにラベリングすることでそのラベルごとに仕分けをして、そのラベルの目的に沿った学習を行うことができるようになります。
AI開発におけるアノテーションとは「教師データを作る作業」のことを指しています。
それでは、教師データとは何を指すでしょうか。
教師というその言葉のイメージから、「入力されたテキスト・音声・画像に対する正しい出力(応答)について記載した正解データ」のことを指します。AIが実利用される際には、「教師あり学習」が利用されることが多いですが、このデータの質の高さがAIの精度を左右するのです。
したがって、AIの出す結果をより良いモノにするためには、教師データの質を高める必要があり、それを作るためには、アノテーションという作業を正確に行う必要があります。そして最も時間と人員を要し、AIの開発を始める多くの企業が困難に直面する工程です。
3.AI開発におけるアノテーションの位置づけ
AI開発では下記図のように、大きく分かれて5つの工程があります。
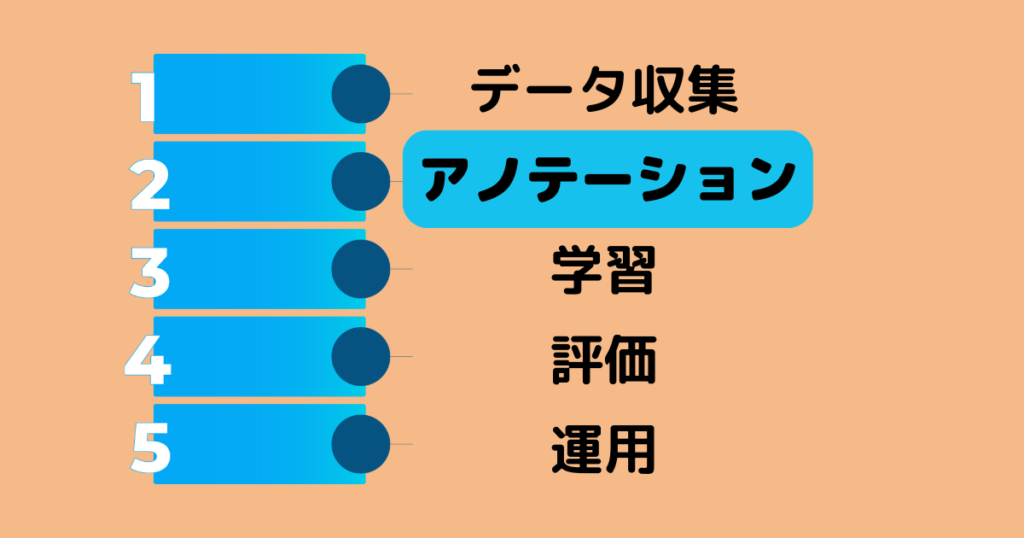
AI開発にはまず、学習させるためのデータが必要になります。しかしそのデータを活用するためには、データの整理をしなければなりません。そしてまだまだ社内でデータが蓄積していない場合は、データの収集から始めることが必要になります。
AI開発にはデータ収集とアノテーションの両輪相まって初めて、次のステップのAIの機械学習を始めることができます。
4.アノテーションのノイズの種類とその原因とは?
ノイズとは?
まず、ノイズとはよく聞く言葉ですが、例えば古いテレビを思い出してみてください。線が入っており、今のテレビの映像のような鮮明さはありません。そして音声も今のテレビより雑音が入っているように聞こえるでしょう。
アノテーションにおけるノイズとは、データのラベルや特徴の誤り、不正確さ、または不適切さのことを指します。つまり、データセット内の情報が本来の状態からずれていることを意味し、機械学習モデルのトレーニングや予測に深刻な影響を与える可能性があります。
ここでは、アノテーションで現れるノイズについて解説します。

特徴ノイズ
誤った特徴、特徴量が与えられたデータを指します。こちらも普段使わない「特徴量」という言葉が出てきました。
特徴量とは、特徴が数値化されたもののことを指します。例えば、「お金持ち」という概念も、いくら資産を持っているか数字で表すことにより、データとなります。つまり、特徴そのものではなく、それが数値化されたものが特徴量となります。
AIの機械学習に置き換えて考えると、画像判別や自然言語(人間が使用する言語のことで、AIの文脈では人工言語・コンピュータ言語と区別して用いられます)を数値化することでデータを特徴量に変換して認識しています。
その特徴量の精度が悪くなることで、機械学習とその予測結果の精度が低下し、AIの精度が悪いという結果に陥ってしまいます。
ラベルノイズ
観測、付与されたデータセット内のラベルが不正確な状態であることを指します。人間のエラーや主観的な判断、またはシステムの誤りによって発生します。例えば、一つのラベルが与えられることを想定したデータセットであるにも関わらず、実際には付与すべきラベルが複数存在する場合が挙げられます。
クラスノイズ
こちらはラベルノイズに準じたものになりますが、クラスノイズとは、データのクラスラベルが誤って割り当てられた状況を指します。クラスは学校で使われるクラス分けという言葉と同じく、分けられたものという意味です。
機械学習の分野においては、データセット内のクラスラベルとは、データが特定のカテゴリに属するかどうかを表すために、クラスラベルが使用されます。例えば、犬、人、電車の画像データセットにそれぞれ、犬の画像が「犬」であることを示すラベルを貼っていくということになります。
つまり、クラスノイズとは、実際にそのデータがそのクラスに属しているはずにも関わらず、間違ったラベルが付与されてしまっている場合や、クラスの分布が偏ってしまっている状況となります。 これらのノイズは、AIモデルの性能に直接影響を与える可能性があります。
5.ノイズの原因とは?
ノイズの原因は多岐に渡りますが、主な原因をここでは解説します。

人間の誤り
アノテーション作業はすべてAIが行っていると思われがちですが、実際は人によって一つずつ手作業で行われている場合もあります。そして、アノテーションを行う作業者のことをアノテーターといいます。
そのため、人為的なエラーが発生する可能性があり、作業者の主観的な判断や作業者間同士での認識のずれ、疲労によるミスなどが原因となります。
作業環境の影響
アノテーション作業を行う環境や条件もノイズの原因となります。作業環境の騒音や混乱、時間的制約、作業者間のコミュニケーションの不足などがミスを誘発し、ノイズを生んでしまう原因となります。
アノテーター間の知識レベルの差
アノテーションを行う人々の知識や経験の差異もノイズの原因となります。正確なアノテーションには十分な知識と理解が必要ですが、アノテーター間のスキルや知識の差異がノイズを引き起こすことがあります。
データの偏り
データセット自体に偏りがある場合、特定のカテゴリやクラスに対するアノテーションの品質が低下する可能性があります。例えば、特定のカテゴリに関するデータが不足している場合、そのカテゴリに関するアノテーションの精度が低くなってしまう可能性があります。
システムの誤り
先ほどアノテーションは人によって行われると述べましたが、自動アノテーションシステムも存在しています。そのシステムとデータ処理パイプラインのエラーも、ノイズの原因となります。これには、データの誤った変換や不適切なフィルタリング、ラベリングアルゴリズムの誤作動などが含まれます。
6.アノテーションのノイズが与える影響とは?
アノテーションのノイズによって下記のような影響が出てしまう可能性があります。

AIモデルが正確に予測できなくなってしまう
ノイズが存在するデータセットを使用してトレーニングされたモデルは、正確な予測を行う能力に制限が生じます。ノイズのあるラベルやアノテーションが含まれることで、モデルは不正確な情報を学習し、正しい分類や予測を行うことが困難になります。
バイアス(偏り)を生んでしまう
ノイズはモデルにバイアスを導入する可能性があります。不正確なデータが多数存在する場合、モデルはそのデータに偏った学習を行い、特定のカテゴリやクラスに対して偏った予測を行う傾向が生じます。
新しいデータを適切に学習できなくなる
ノイズが存在するデータセットを使用してトレーニングされたモデルは、汎化能力が低下する可能性があります。つまり、モデルが新しいデータに適切に対応できなくなる恐れがあります。ノイズのあるデータセットでトレーニングされたモデルは、現実世界のデータに対して適切な予測を行うことが難しくなります。
決定プロセスを不透明にしてしまう
ノイズがモデルの解釈性を低下させる可能性もあります。ノイズのあるデータセットでトレーニングされたモデルは、そのノイズに影響を受けて予測を行うため、モデルの決定プロセスが不透明になります。
これらのようにノイズが与える影響は多岐に渡ることが分かります。
その影響を踏まえると、アノテーションのノイズは機械学習プロジェクトに深刻な問題を引き起こす可能性があります。ノイズの影響を最小限に抑えるためには、品質管理プロセスの強化やノイズ対策の導入が重要です。
7.アノテーションのノイズの対処法
アノテーションのノイズへの対処法は、原因が何かわかっている場合は対処法が明確になるでしょう。一方、原因がわからない場合は、再度アノテーションを行うことも視野に入れておく必要があります。

アグリゲーション(Aggregation)手法を用いる
アグリゲーションは英語で「集合」「集合体」という意味があり、日本語の多くの文脈では「複数のモノをまとめること・まとめたもの」を指すことが多いです。
IT業界で使われることが多い言葉ですが、この文脈に即していうと、複数のアノテーターが同じデータにアノテーションを行い、結果を統合することでノイズを低減させます。アグリゲーション手法には、多数決、平均、重み付けなどがあります。
アノテーションは通常複数人で行うことが多いため、この対処法は効果的です。
アノテーターをトレーニングする
アノテーターに対して適切なトレーニングを提供することで、一貫性のあるアノテーションを得ることができます。トレーニングは、タスクの理解、基準の適用、ノイズの特定方法などを含むことがあります。
アノテーションには高い技術が必要となるので、慣れていない場合はアノテーションサービスを利用したり、クラウドワーカーへの外注も一つの方法と言えるでしょう。
外部データの利用を検討する
アノテーションのノイズを低減するために、外部データソースを利用するという手段もあります。これにより、データセットの多様性が増し、ノイズの影響を軽減することができます。
品質管理の強化
アノテーションプロセス全体に品質管理手法を導入することで、ノイズを最小限に抑えることができます。これには、定期的な品質チェック、フィードバックループの実装、アノテーション基準の厳密な遵守などが挙げられます。
アノテーションの再検討と修正
ノイズのあるアノテーションを再検討し、修正することで、データセットの品質を向上させることができます。これには、アノテーションの再評価や、誤ったアノテーションの除去が含まれます。
アクティブラーニングを行う
モデルが不確かなデータを識別し、それらのデータに対して追加のアノテーションを要求することで、アノテーションの品質を向上させることができます。
上記のように新たに手作業でアノテーションを施すとなると、コストがかさんでしまい、時間もかかってしまいます。アクティブラーニングを行うことにより、データ全体にアノテーションを施す必要がなくなるため、その分のコストと時間を軽減することにつながります。
まとめ
いかがでしたでしょうか。AI開発において、質の高いアノテーションが施された教師データのデータセットと少しでも多くのノイズを削減することがAIの精度を左右することがお分かりいただけたかと思います。
harBest(ハーベスト)ではDX推進の必要性を感じていてもなかなか踏み出せないお客様やAI開発を検討していてもどこから手に付けていいか分からないお客様に寄り添い、その一歩を踏み出すための課題設定からAI実装まで包括的なサポートをしております。
AI開発において重要な教師データの作成には、弊社の多数のクラウドワーカーによる高品質なデータ作成とWEBでの発注による、スピーディーかつコストパフォーマンスの高いデータセットの準備が可能です。 AI開発につきまして下記よりお気軽にお問い合わせください。