【大規模言語モデル(LLM)開発】データセットの入手方法について詳しく解説!

昨今、AIの有用性やAIがビジネスやクリエイティブに与える影響が叫ばれて久しいですね。
AIの実用性に関しては、どこまで実現できるのかについて疑問に感じている方も多いでしょう。一方で、AIが実現しうる効率化や人間の業務を代替してくれるという、AIの可能性から目が離せないという方も多いと思います。
今回は、最近AIの領域で最も注目されている大規模言語モデル(LLM)について解説します。私たちが日常的に話したり、書いたりするのに使用する自然言語の質問に対して回答を自動的に生成してくれる生成AIの一種です。
今後ビジネスでの活躍が期待される大規模言語モデル(LLM)を開発するにあたって、最も重要なデータセットをどのように入手するかということについて詳しく解説します。
目次
大規模言語モデル(LLM)とは?
大規模言語モデルとは、英語のLLM(Large Language Models)から訳され、大量のデータをAIのディープラーニングの技術を用いてトレーニングした基盤モデルのことをいいます。
人間が普段使用する自然言語における、文章や単語の出現確率をモデル化したもので、文章作成や応答など自然言語処理で用いられています。
以前より自然言語モデルは存在していましたが、データ量・計算量・パラメータ量が大幅に増加、大規模になったことによって大規模言語モデルと言われており、精度が格段に向上しました。
大規模言語モデル(LLM)がどのように活用されているのか
最近では、様々な業種で大規模言語モデルの開発が盛んになってきています。
ビジネスにおいては、顧客の要望・質問に応じて適切な回答や提案を生成してくれるチャットボットの活用が進められています。
顧客対応だけでなく、社内での利活用も進められています。例えば、社内の色んな部署に散らばってしまっている情報やデータについて、戦略を練るためにそれをまとめてプレゼンテーションする機会がある人も多いでしょう。その場合、「○○の情報についてまとめてください」のように、調べたい情報について指示をするだけで、数分でレポートをしてくれます。

社内で活用する場合は、個人情報などを多く扱う企業の場合は個人情報漏洩や機密情報漏洩のリスクがあります。通常基盤モデルが公開されているLLMを活用する形になりますが、プライベートクラウドサービスや自社運用のシステム上で動作させることで、上記のリスクを抑えることができます。そのような大規模言語モデル(LLM)はプライベートLLM(またはプライベートAI)と呼ばれています。

このようにビジネスだけでも大規模言語モデル(LLM)は大きな可能性を秘めています。
大規模言語モデル(LLM)開発には品質の高いデータが必要
大規模言語モデル(LLM)を開発するためには、まずは利用用途の策定から始まりますが、同時に開始しなければならないのが、データの収集と作成です。
様々なデータソースから自然言語コーパスを大量に収集することで、自然な言い回しを学習し、アウトプットをすることができるようになります。しかし、ビジネスや専門性の高い事柄については、別途学習させる必要があります。
AIは有能ではありますが、学習内容や学習方法によってはウソをついてしまうことがあります。このことをハルシネーションといいます。

先ほども話に出たように、モデルは学んだことから文章の並びや、単語が文章の中のどこに出てくるかを出現確率で学習しています。データソースの中には、インターネットから収集したものも多く含まれているため、ネット上で誤って使用されている言葉を使ってしまったり、同じ事柄に対して真反対のことをそれぞれ学習させてしまうと、時によっては正しい/正しくない結果を提示してしまったりする可能性があります。
専門的な内容の場合は、モデルの精度を高めるためにも、人の手によってアノテーションされた正確なデータセットを準備して学習させる必要があります。アノテーションに関しては、以下の関連記事をご覧ください。
【関連記事】
・https://harbest.io/documents/459/
・https://harbest.io/documents/495/
・https://harbest.io/documents/525/
品質の高いデータセットの入手方法とは?
大規模言語モデル(LLM)には膨大かつ品質の高いデータセットを準備する必要があることがお分かりいただけたと思います。
それでは、品質の高いデータセットはどのように準備すればよいでしょうか。

クラウドソーシング
オンラインプラットフォームを利用して、クラウドソーシングでデータを収集する方法です。アノテーション、テキストの収集など、さまざまなタスクを依頼することが可能です。
クラウドソーシングは、人手による収集よりもコストが低い場合がありますが、作業者が多い場合の品質管理が難しくなる可能性や、タスク設計を緻密に行う必要があります。
自社でデータセット作成
社内でこれまで蓄積したデータを使用、または学習のためにデータセットを作成するという方法は一番安心感があるでしょう。しかし、データ作成については膨大な時間がかかるだけでなく、その結果人件費がかさんでしまう、ということがよくあります。
専門的なデータセットを作成するために自社で完結した方がよいという場合もありますが、アウトソーシングする方が品質が高く、コストも抑えられるという場合もあります。様々な方法を検討すると良いでしょう。
オープンソース/ライセンス付与されたデータセットを利用する
多くの研究機関や、官公庁・自治体、大学、企業、AIデータセット販売会社などによって、誰でもアクセスできるインターネット上にて無料でダウンロードできるようになっている、または有料で販売されています。
ウェブクローラーにより自動収集されたものではなく、人の手が一度入っているデータセットのため、データ自体の品質が高いだけでなく、専門知識や特定の領域に関する情報を含むデータを入手することができます。
データ収集サービス
データ収集サービスでは、様々なソースから膨大なデータを集約・整理することを専門としているため、データが様々な言語、地域、トピックに及び、多様性を持たせることができます。
データ収集サービスを利用することで、他の方法よりかかるコストがかさんでしまう可能性がありますが、データの質と多様性を確保することができ、アウトソーシングすることで開発担当がモデル開発に時間を多く割くことができるだけでなく、社内の人件費を抑えることにつながり、場合によってはコストが安く済むということも考えられます。
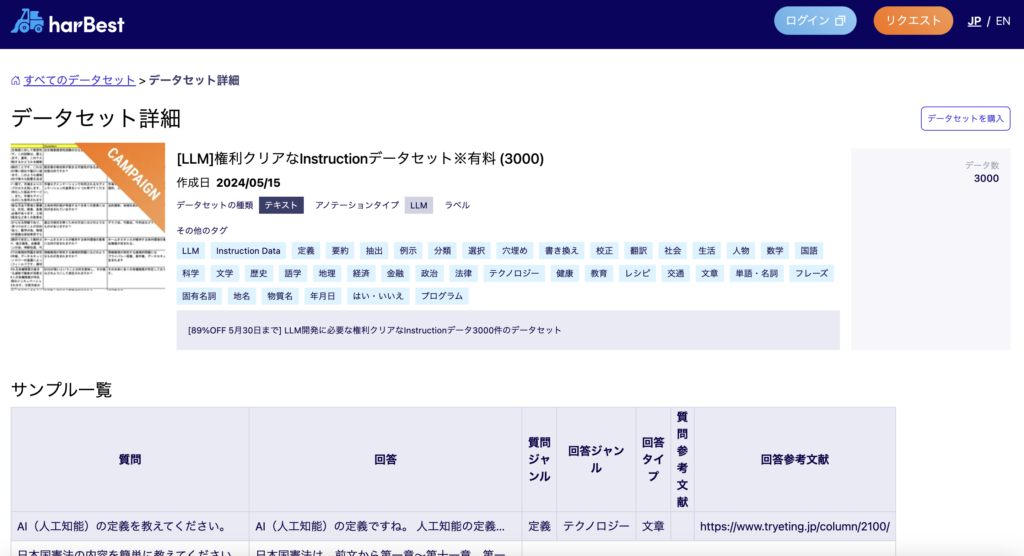
harBestが提供するLLMデータセット
harBestでは、低価格で数千件のLLMデータセットを提供しています(一部無償有り)。
ご興味がある方は、是非ご連絡ください。
◼︎harBest Datasetsプラットフォーム
https://data.harbest.io/ja/datasets/llm_dataset_2
まとめ
大規模言語モデル(LLM)開発においては、データセットの品質とデータの量が重要であることがお分かりいただけたと思います。また大規模言語モデル(LLM)開発にあたっては様々なデータ収集方法があることがお分かりいただけたと思います。
harBest(ハーベスト)では、AI開発、大規模言語モデル(LLM)開発に欠かせないデータセットの配布、販売を行っています。また、販売しているデータセットだけでなく、皆様からのリクエストにお応えしてデータセットの作成も承っております。専門的なデータセット作成にお困りの場合、ぜひご相談ください。
現在、権利クリアなLLM開発用テキストデータセットを2週間限定89%オフで販売しております。この機会にぜひご利用ください。 AI開発につきまして随時ご相談を受け付けております。下記よりお気軽にお問い合わせください。