日本語LLM開発のための日本語データセットの重要性について解説!

ここ数年でAIの領域で最も注目されているのが生成AI(Generative AI)でしょう。我々が普段話したり、書いたりするのに使う自然言語でプロンプトを作成して指示を出すことで、テキスト、画像、動画、音声などを生成することができます。
生成AIの技術により、エンジニアにとって開発のスピード向上、業務の効率化や自動応答技術の発展などを可能にしています。その中でもChatGPTのようなテキスト生成AIの登場が生成AIの認知度を高め、IT企業のみならず、非IT企業、教育現場、個人など幅広く利用されています。多くの人が利用するテキスト生成AIの中心にあるのがLLM(大規模言語モデル)です。(LLMについて解説している記事はこちら)
LLMの技術は長い文章を要約、企業のサイト上のチャットAIで使われているような質問応答、文章の翻訳、コンテンツ生成などに利用され、幅広くビジネスに活用されています。しかし、まだまだ日本語など英語以外の言語環境で利用した際の生成AIの精度は高くないと言われています。なぜでしょうか。
それは、これまで海外企業で英語中心にLLM開発が進んできたためです。一方で日本企業では日本語特化のLLM開発が進められており、続々とIT企業が製品を発表しています。
今回は生成AIの技術の中心ともいえる、LLM(大規模言語モデル)について、日本語LLMと日本語LLMの利用・開発に欠かせない日本語LLM用のデータセットについて詳しく解説します。
目次
日本語LLM(大規模言語モデル)とは
LLM(大規模言語モデル:Large Language Models)とは、膨大な数のデータセットとAIのディープラーニング(深層学習)の技術を用いて構築された言語モデルのことをいいます。
言語モデルは、文章・単語の出現確率を用いてモデル化したもので、ChatGPTなどのようなテキスト生成AIのような文章作成などの自然言語処理(人間が使用する言語 :Natural Language Processing、NLP)で利用されています。
日本語LLMとは、日本語での入力と出力に特化したAIモデルのことを指します。
生成AIは英語の方が精度高い?

現在、多くの人々が利用するLLMは、Microsoft、Google、OpenAI社など欧米企業が主体となって開発が進んできました。そのため、ほとんどのLLMはWEB上にある英語によるデータを学習して開発されています。
生成AIは英語以外の言語からも単語や文章を学習しており、「○○語に翻訳して」と指示を出すと翻訳してくれます。
しかし、生成AIのサービスの多くは始まった当初英語でしか対応していない、ということがよくありました。つい最近ではApple社が新たな機能としてApple Intelligence(アップルインテリジェンス)という生成AIのサービスを発表しました。当面は英語でのみの提供となるそうです。
英語は世界共通語という認識であり、開発が英語で進められるだけでなく、どの言語よりも膨大なデータが存在しているため、英語以外で入力・出力したときに比べて、英語の方が精度の高い回答を得ることができます。
時に不自然な回答をしてしまう生成AI
例えば、調べたいことがあってChatGPTに教えてもらいたい時に、普段日本語を使っている人は日本語で入力するでしょう。これはネットで検索するときも同様です。
最近生成AIを使い始めた人は、ChatGPTで日本語を入力した時に日本語で返答してくれるので「ある程度の質が担保されているのでは?」と感じる方も多いでしょう。
しかし、生成AI黎明期から使用している人や、使用頻度が高い方にとっては、たまに単語がうまく翻訳されておらず英語で返答される、不自然な回答になっている、または、意味は分かるけど微妙だな、と感じられた経験があると思います。
それは日本語のデータや教師データ(教師データについてはこちら)
の学習が英語のデータに比べて圧倒的に少ないことから発生しています。
日本語に特化したLLMは本当に必要か?
なぜあえて、「日本語LLM」のように、日本語に特化したLLM、日本語ネイティブなLLMという表現をするのでしょうか?

日本語LLMが必要になる理由①:日本語の文法や表現
どんな言語も独自の文法、表現があります。
例を挙げるときりがありませんが、使用する文字、形容詞と名詞の位置、日時を表す言葉を付ける位置などの語順など言語によって異なっています。英語と日本語と比べるだけでもその違いは一目瞭然でしょう。
日本語は文脈に大きく左右される言語のため、ある単語の意味が文脈によっては他の意味を持ち得ます。
それだけでなく下記のような日本語の特性が現状のLLMの回答が時に不自然となってしまう理由となっています。
・単語の意味が文脈に左右される
・省略が多い言語(主語や目的語が頻繁に省略される)
・ひらがな、カタカナ、漢字、数字、アルファベットなど多くの文字を使用する。
・「象は鼻が長い」「僕はうなぎだ」「こんにゃくは太らない」構文にみられるような、日本語における主語と助詞の使われ方の複雑さ。
他の言語に直す際に直訳することができず、日本語学でもこの論争は長い間続けられており、解決していない。
・「足と脚」のような同音・同訓異義語が存在する。
・方言の多様性。例えば、標準語で「自転車を押す」という表現は、名古屋周辺の地域では、「自転車を引く」というように表現します。同じ意味の単語であっても日本全国で異なる単語の組み合わせになります。
以上に挙げたような日本語の特性により、一般的に使用されている英語LLMを用いて日本語に翻訳して出力しようとすると、文意が誤って捉えられてしまい、不自然な回答になってしまう可能性があります。
日本語LLMが必要になる理由②:日本語で蓄積された情報や知識が必要
ネット上には様々な情報が存在しています。しかし、言語とその言語が使われる社会背景は密接なつながりがあるため、必ずしも言語が違うだけで翻訳すれば誰でも理解できる、というものではありません。
例えば、日本語でビジネスメールを書く際は、「いつもお世話になっております」などの言葉から書き始めますが、英語にはそれを直訳したものを記載するかというと、そうではありません。一方で、英語のビジネスメールでBest Regardsのようなメール文末に記載するものも、日本の商習慣にはありません。
したがって、日本語と日本の文化、社会において蓄積された情報や知識をデータとして学習しなければ、日本語でAIを利用していく上では不自然で不完全なままになってしまいます。
日本語で生成AIを使用していくためには、英語LLMに日本語に翻訳指示するだけでは不自然さが残ってしまいます。
不自然さを払拭、または生成AIが回答をして誤解を生まないようにするためには 日本語LLMがなければ、日本語での生成AIの利用が制限されてしまうどころか、使用していく意味を見失ってしまうことにもなりかねません。
また、指示文として正しく入力された情報を読み取り、誤った情報や不自然な表現を避けた精度の高い日本語LLMを開発するためには、質が高く、専門性の高いデータセットの学習が欠かせません。
続々と公開される日本語LLM
日本語LLMの開発は日々進んでおり、IT企業が続々と日本語特化型LLMとそれに関連するサービスを提供しています。日本のIT企業や、大学と企業の産学共同グループなどから続々と日本語LLMが発表されています。
OpenAI社のChatGPTでは2024年4月15日よりGPT-4日本語カスタムモデルが提供開始されました。また同時に日本独自のニーズに応えるため、アジア初のオフィスOpen AI Japanが開設され、日本・日本語特化を進めています。
日本語モデルとは一口に言っても、テキスト生成に使うためのモデル、入力テキストの処理に使うモデルなど、英語LLMに日本語で追加事前学習を行ったモデル、英語LLMに日本語で指示チューニングのみ行ったものなど、様々なモデルが公開されています。
LLM開発やLLM利用にあたり、使用用途やどのように学習させているかなど参考にするとよいでしょう。(AI開発についてはこちら)
日本語LLMに使用できるデータセット・コーパス
先ほど述べたように、最近では続々と日本語LLMが多くの企業や研究室で開発、公開されています。LLM開発にあたって重要なことはデータの質と量が大きく影響するとお伝えしてきました。
それではどのようなデータセット・コーパスがあるのでしょうか?以下ではごくごく一部のデータセット、コーパスをもとに見ていきます。

日本についてのデータセット
日本のことについて、日本語で書かれたデータセットがより精度の高い回答を生成することにつながります。政府や民間企業、大学、メディアがデータセットやコーパスを提供しています。
e-GOVデータポータル(以前の名称はDATA GO JP)https://data.e-gov.go.jp/info/ja
日本政府・中央行政により提供、デジタル庁が整備、運営するオープンデータポータルです。公共データを広く公開することにより、国民生活の向上、企業活動の活性化等を通じ、我が国の社会経済の発展に寄与する観点から、機械判読に適したデータ形式を、営利目的も含めた二次利用が可能な利用ルールで公開しています。
人口、社会保障、運輸、行財政、企業、家計、経済、国際、司法、教育、国土、気象など日本における様々なデータを検索して探すことができます。データも画像や動画、テキストなど合わせて約2万項目ものデータセットが提供されており、2次利用が可能となっています。
国立情報学研究所 情報学研究データリポジトリhttps://www.nii.ac.jp/dsc/idr/datalist.html
民間企業の提供しているデータセットが一覧になっているサイト。LINEヤフー株式会社の提供するYahoo!データセットや楽天グループ株式会社が提供しているデータセット、弁護士ドットコムの株式会社が提供する法律相談データのデータセットなど多岐にわたるデータセットが提供されています。
また、立命館大学が提供している浮世絵デジタル情報や、大阪大学が提供する対話エージェントと人との対話の様子を収めたマルチモーダルコーパスなどの研究機関から提供されているデータセットもあります。
日本語データセット
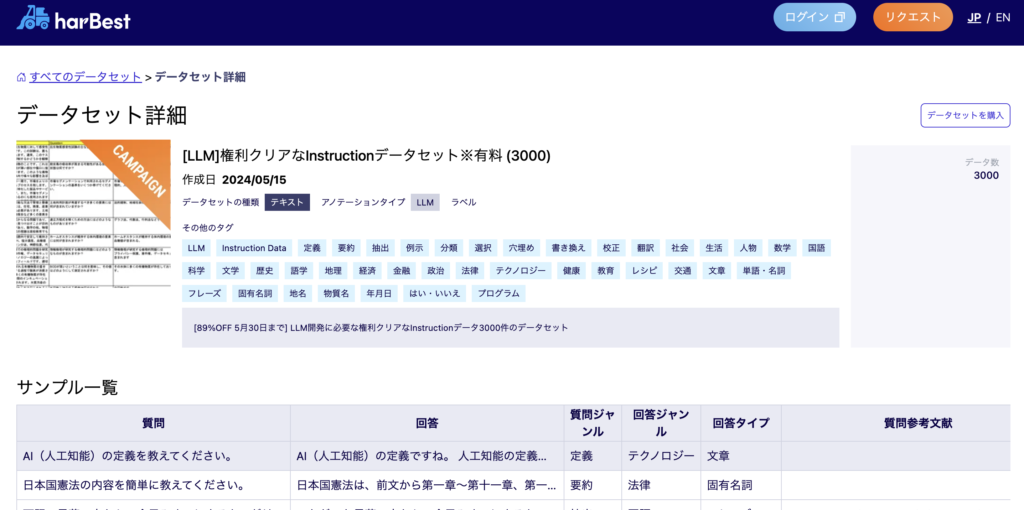
harBest-LLM-Datasets https://data.harbest.io/ja/datasets/llm_dataset_2
APTO社が作成し、2024年に公開された日本語Instruction Data。日本の企業だけではなく、グローバル企業へも提供。
Japanese CC-100 https://metatext.io/datasets/cc100-japanese
Facebook社(現・Meta社)が構築し、2020年に公開された日本語データセット。2018年のCommon Crawlのスナップショットから作られています。
mc4(Japanese C-4)https://huggingface.co/datasets/allenai/c4
Google社の多言語データセットで、日本語用に前処理されたもの。CC-100よりも1件当たりのテキストデータが長いのが特徴。
上記で紹介したものは代表的なデータセットやコーパスとなります。上記のみならず、特定の業界の専門用語や特定の状況に合わせたデータセットの作成等がLLMの精度向上へつながります。
そのようなデータセットは自社でデータセットを作成するには膨大な時間とコストがかかってしまう場合があるため、データセットを作成するサービスを利用すると良いでしょう。(詳しくはこちら)
日本語LLMの今後の可能性
日本語LLMは今後さらに開発が進んでいき、それにより生成AIの精度はさらに高まるでしょう。生成AIは今でも企業で活用され、主に業務効率化に役立てられていますが、複雑な日本語体系を学ぶことで、チャットボットや音声での対応など幅広くより創造性の高い業務に応用することができるようになると考えられます。

日本語で専門的なタスクをこなす
日本語LLMの精度の向上はデータ数・パラメータ数だけでなく、法律、医療、企業独自のナレッジ等の専門的な知識のデータセットによって、特定のタスクやデータセットに対して適用させるファインチューニングすることで、ビジネスなどで実践的に活用ができるようになります。
方言や俗語(スラング)、感情を理解する
人の話す自然言語には感情が付随していたり、その人の言葉が出身に応じて方言、年代に応じたスラングを使った文章になっていたりすることがほとんどです。
これらを理解できるようになることで、日本語で生成AIを使用する場合さらに精度の高い回答を期待できます。
日本語LLMを搭載した生成AIは今後当たり前のものになり、より生活やビジネスに密着した存在となります。 今後日本国内のビジネスで優位性を確保し続けるためには、日本語LLMで学習した生成AIが欠かせないフェーズに入っています。そして、AIモデルの質を高めるためには、データの量・データの質が大きく関わっているのです。日本語LLMが今後も質を上げていくためには、日本語のデータセットが欠かせません。
APTOが提供するLLM Instruction Data
APTOは、LLM開発のFine Tuningに必要なInstruction Dataを日本の大企業だけではなく、グローバル企業にも提供をしています。Instruction Dataにお困りの企業様は是非ご連絡ください。
◼︎Instruction Data提供
https://prtimes.jp/main/html/rd/p/000000062.000053927.html
◼︎harBest Datasetsプラットフォーム
https://data.harbest.io/ja
まとめ
最後までご覧いただきありがとうございました。本コラムでは、日本語LLMと日本語LLM開発に欠かせないデータセットについて詳しく解説しました。日本企業や日本市場にとっては、目を逸らすことのできない技術です。この1年で日本語LLMは格段に進化しており、今後はさらに様々なシーンで活用されていくことが予想されます。
harBest(ハーベスト)では、日本語LLM(大規模言語モデル)開発、AI開発に欠かせない、データセットの配布、販売を行っています。お客様のビジネス領域や要望に合わせた専門的なデータセットの作成もご依頼も承っております。高品質な専門的なデータセット作成にお困りの場合、ぜひご相談ください。
AI・LLM開発とそれに付随するデータセット作成につきまして随時ご相談を受け付けております。下記よりお気軽にお問い合わせください。