大規模言語モデル(LLM)の指示追従性能の精度を高めるLLM学習用データセットを公開
生成AIの推論能力を高める「Reasoning Data」「Mathematical Data」に続き、本データも無料公開いたしました。APTOは今後も、AIデータを通じて事業活動を支援して参ります。

株式会社APTOは、LLMの「指示追従性能」を改善させるためのデータセットの開発を行いました。
LLMの性能は日進月歩で向上している一方、依然として指示に従う能力が課題視されています。
指示追従機能改善用LLMデータセット開発の背景
LLMを活用する際に、たとえば以下のように複数以上の指示を出されることがあると思います。
・メディア運営者が本やweb記事の紹介を行うためにLLMに要約を書かせる。その際、読みやすいように「3行にまとめて」など行数や文字数を指示する。更に書かせたい内容の指示も列挙する。
・社内業務を効率化を目的に、LLMに書類チェックをさせる際、精度を上げるためにと次々とルールを増やす。
・LLM学習のために合成データを生成する際、品質を担保するために複数のルールを指示、その品質を改善するため更に指示するルールを増やす。
・同様に、LLM-as-a-judgeを行う際に評価項目を複数作り、さらにjsonフォーマットなどを細かい出力形式での出力を指示する。
・LLMに論文やレポート、IR資料の調査・要約をお願いする際に要約して欲しい内容をいくつかルールを設けて指示。
このようにルールや指示が複数あると、指示やルールを無視し、望ましいアウトプットに繋がらない経験をされた方も多いと思います。
そこで、当社の指示追従能力改善のノウハウを活かし、通常の指示に加え、複雑な指示を含んだ、
Instruction データセットの開発を行いました。合成データで作られた指示追従データの中から、さらに人手での品質管理を経た222件を厳選し、huggingface に公開しました。
https://huggingface.co/datasets/APTOinc/instruction-following-dataset
本データセットの内容
データセットの構成としては Instruction Tuning に必要な「質問」「回答」、その会話の内容を示す「ジャンル」タグに加え、「質問」内の指示内容を抽出したリストの「指示内容」、およびその指示の数を入れた「指示数」で構成されています。

このデータセットには「複雑な指示」にあたる質問も含められております。ここでいう「複雑な指示」とは、指示が2つ以上になるケースを指しています。LLMへの指示を行う際、具体的な条件付けや出力形式の指定を行うケースが多く、そのような指示に対してより追従性を見せるためのデータとなっております。
また、データを効率よく作成すべく、指示の複雑化を行った合成データを作り、加えて以下の2プロセスを踏まえることで品質を担保いたしました。
1.GPT-4.1を用いて指示に従えているかを評価
2.AIの判断では不十分な点に対して、更に人手での確認・修正を行なう
以下はその複雑な指示の例になります。

「ジャンル」ラベルについて
質問・回答の一連の会話内容に対して、どのような題材を取り扱っているのか、会話内容のタグを付与しています。ラベルは以下のものとなります。

指示内容のラベルについて
質問内における指示の仕方の属性を定義し、ラベルを付与しています。このデータセットで、より学習・評価・分析を行いやすくすベく作成したタグとなります。ラベルは以下のものとなります。

データの性能検証結果
このデータセットを用いて学習を行ったモデルについては、指示追従ベンチマーク IFEval の多言語版である M-IFEval ※1で評価を行いました。
具体的な検証方法は以下のようになります。
1.複雑な指示を含む合成インストラクションデータを学習データとして Fine Tuning(以下FT)
2.M-IFEvalで日本語のベンチマークのみを用いて学習前後のモデルを評価。出力が異なることもあるため、同様の評価を4回した上でその評価スコアの平均を比較。
日本語における指示追従性能の改善を評価するため、以下の高い日本語性能を持つモデルに対して評価を行いました。
・shisa-ai/shisa-v2-qwen2.5-32b ※2
・ deepcogito/cogito-v1-preview-qwen-32B ※3
上記のモデルに対して学習を行ったところ、実際に指示追従能力の改善が見られました。
以下、そのスコア表となります。
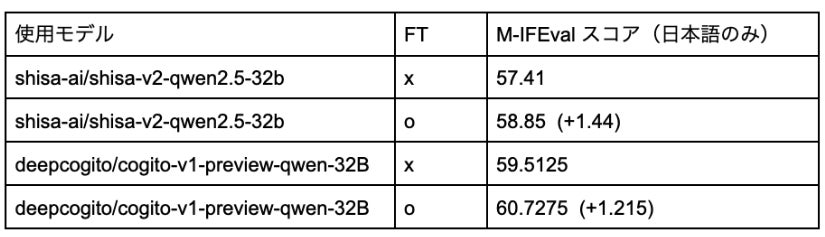
実際に作成したデータセットの一部には json 出力の指示や、箇条書きを指定するなどのフォーマットに対する指示も含んでおり、そういったベンチマークと類似するデータが性能改善に寄与したと考えられます。
※1: https://github.com/lightblue-tech/M-IFEval/tree/main
※2: https://huggingface.co/shisa-ai/shisa-v2-qwen2.5-32b
※3 :https://huggingface.co/deepcogito/cogito-v1-preview-qwen-32B
今後のデータセット作成について
マルチターンにおける指示追従性能を評価する MultiChallenge ※4 や既存の指示追従ベンチマークが十分でないことから作られた IFBench ※5 など、指示追従の性能に関する課題がより深く議論されています。
加えて、Claude CodeやGemini CLIなどが台頭している中、LLMにプログラミングをさせた方でも、プログラムの設計ルールやテストなどを無視するといった経験をされた声も多いようにも見られます。
LLMの技術進歩は極めて早く、転々とするニーズや技術課題を意識しながら、他のケースに特化した指示追従に関するデータセットを作る必要があると考えております。
今後の技術動向やお客様のニーズに応じて新たなデータセットの作成を進めております。
※4: https://arxiv.org/html/2501.17399v1
※5: https://arxiv.org/pdf/2507.02833